Rehosting, a cornerstone in the evolution of software development and deployment, has traditionally enabled the concurrent operation of multiple operating systems and applications on the same physical hardware. This approach, often employed through virtual machines (VMs), enhances efficiency, scalability, and resource utilization.
However, in contemporary software development, the focus is shifting towards containerization, as exemplified by orchestration platforms like Kubernetes. While Kubernetes excels in abstracting the deployment environment from the host system, offering superior flexibility and resource management, it’s noteworthy that not many Kubernetes platforms currently support running VMs directly on Kubernetes.
This limitation is particularly relevant for traditional applications structured as monoliths, such as Pedal, a Java monolith web application. Pedal’s requirement to utilize an application platform based on Kubernetes underscores the need for compatibility between VM-based legacy applications and modern containerization practices.
Red Hat® OpenShift®, powered by Kubernetes, transforms legacy applications into flexible, scalable, and easy-to-manage services. By segmenting these legacy applications into containers, you can streamline development, testing, and production environments — and make the application more resilient to underlying infrastructure changes.
This hands-on article demonstrates how to migrate Pedal, a legacy Java application, to OpenShift. It also demonstrates how Argo CD (OpenShift GitOps) can facilitate building and deploying the application, ensuring a consistent and reliable delivery pipeline.
Setting up Pedal on OpenShift
You’ll start by creating an OpenShift application. But first, you need to create a project. This project is a namespace for the application and contains all of the application’s associated resources.
To create a project, navigate to the Home → Projects page on the OpenShift console and click Create Project. Enter a name, display name, and description. Then, click Create. Alternatively, you can select Create Project from the bottom of the project switch drop-down list.
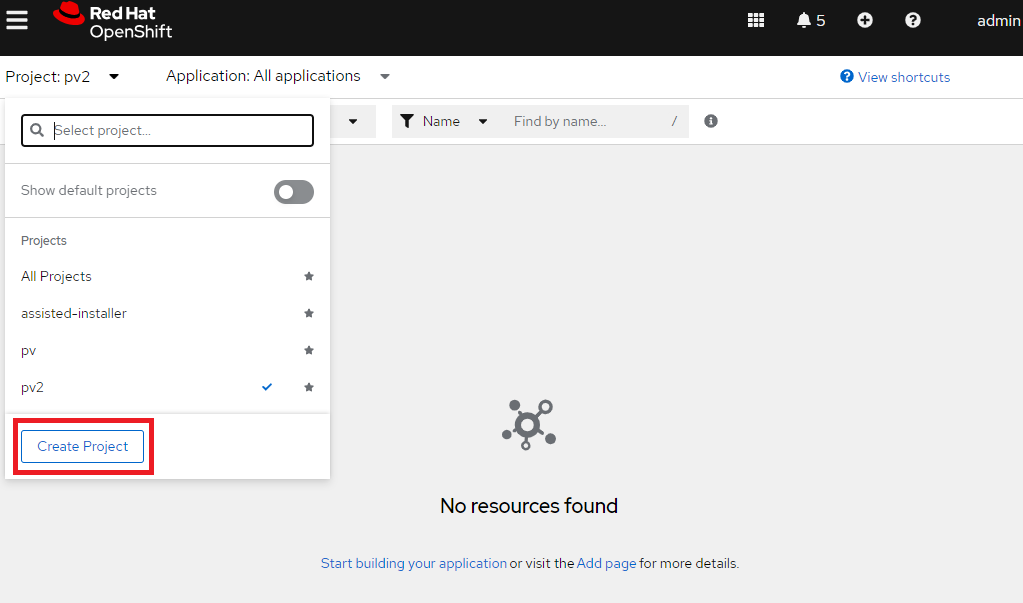
Figure 1. Creating a new project in the OpenShift console.
When preparing to build your application in OpenShift, it’s essential to understand the relationship between your project and the Git repository. Rather than simply connecting your project to a Git repo, you’ll use the Git repository as a source for building an image. This image, in turn, is linked to your OpenShift project.
It’s also important to note that within a single project, you can manage multiple images, each potentially built from different source Git repositories. Additionally, by default, the project’s creator receives administrator rights for creating resources within it. Before initiating this process, ensure you possess the roles and permissions to create and manage resources in OpenShift.
Additionally, having a well-thought-out plan for your Git repository’s structure and the required build and deployment configurations for your application is advantageous for a streamlined development process.
Log into the OpenShift web console and switch to the Developer perspective. Navigate to the +Add page from the navigation menu on the left. Here, you’ll find several methods to create a new application. Select the Git Repository option.
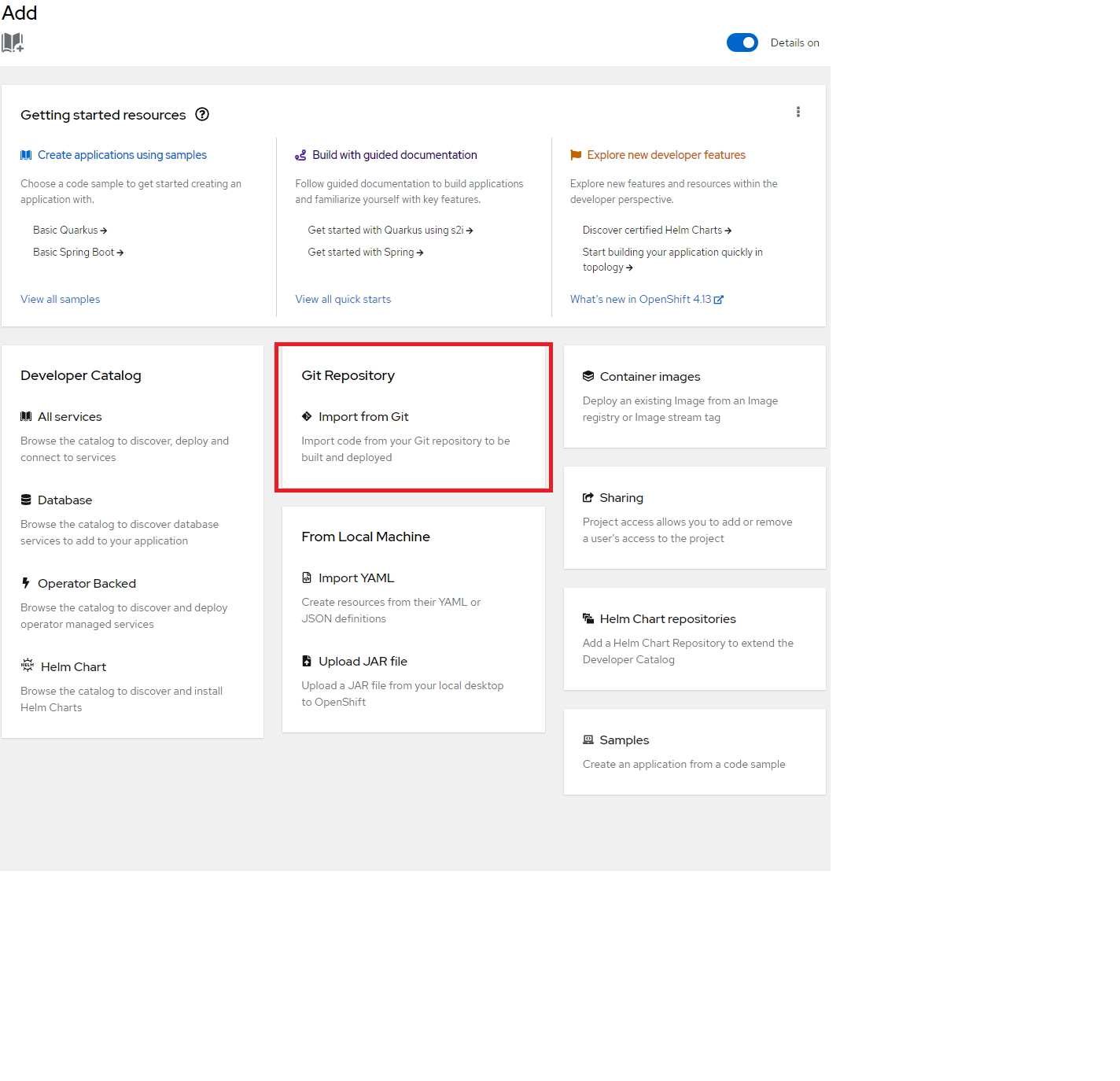
Figure 2. Selecting Git Repository from the Getting started resources page.
When setting up your project in OpenShift, you’ll be prompted to enter the URL of your Git repository. If your repository is public, OpenShift can automatically detect and select the appropriate builder image corresponding to your application’s language or framework.
However, the process requires additional steps for private repositories to ensure secure access. In this case, you’ll need to provide credentials, typically handled through OpenShift’s Secrets object type. This feature allows you to store and manage sensitive information like authentication credentials securely.
By configuring secrets for your private Git repository, OpenShift can access and use the repository to build your application. This maintains the security and integrity of your credentials.
If the builder image isn’t auto-detected, you can manually select the appropriate builder image from the list. This image is crucial, providing the necessary environment for building and running your application.
After entering the Git URL for Pedal and selecting the builder image, you can further customize the deployment configurations like environment variables, routing, and build configurations. The Build Configuration section lets you specify the branch to use, the context directory (if your application isn’t in the repository’s root), and other build-related settings. You can also configure the deployment triggers here, including whether to trigger a new deployment when the image or configuration changes.
Lastly, review all the configurations and click Create to create the application.
When setting up your application in OpenShift, the platform will first create a BuildConfig, which initiates an initial build to create the application image. Additionally, in the latest versions of OpenShift, particularly from 4.14 onward, a standard Kubernetes Deployment is used instead of the previously used DeploymentConfig. The shift to Deployment aligns OpenShift with standard Kubernetes practices, ensuring more streamlined and up-to-date deployment processes.
This Deployment is responsible for deploying the application once the image is ready, offering enhanced management and scalability features in line with current Kubernetes standards.
The application, once deployed, will actively run in OpenShift. You can comprehensively monitor and manage its deployment state through the OpenShift web console. A key feature of this console is the Topology view, accessible from the Developer perspective. This view provides a visual representation of the applications and services in your project, offering an intuitive and interactive way to understand the current state of your deployments. Each application or service is represented by a roundel, a dynamic and color-coded icon that provides immediate visual feedback about the status and health of each deployment.
The roundel within the Topology view is particularly informative. Different colors on the roundel indicate an application’s operational status. For instance, blue might signify that the application is running without issues, while other colors may indicate various states or alerts. Furthermore, the roundel includes icons that represent the type of application or service, such as a database, server, or custom application, allowing for quick identification of the resource at a glance. This feature is incredibly useful in environments with multiple applications or services, enabling you to discern the nature of each component in your project quickly.
In addition to these features, the roundel offers interactive capabilities. By clicking on or hovering over a roundel, you can access detailed information such as logs, current operational status, and more. This functionality is crucial for in-depth monitoring and troubleshooting. The roundel can also display the replica count, showing how many instances of a particular service or application are running — vital for understanding scalability and load distribution.
The Topology view in OpenShift offers significant customization options for the roundel display, including switching between resource types, replica counts, and other relevant information. These customization capabilities ensure flexibility, enhancing the user experience and making the Topology view a powerful tool for comprehending and managing the intricacies of modern application deployment.
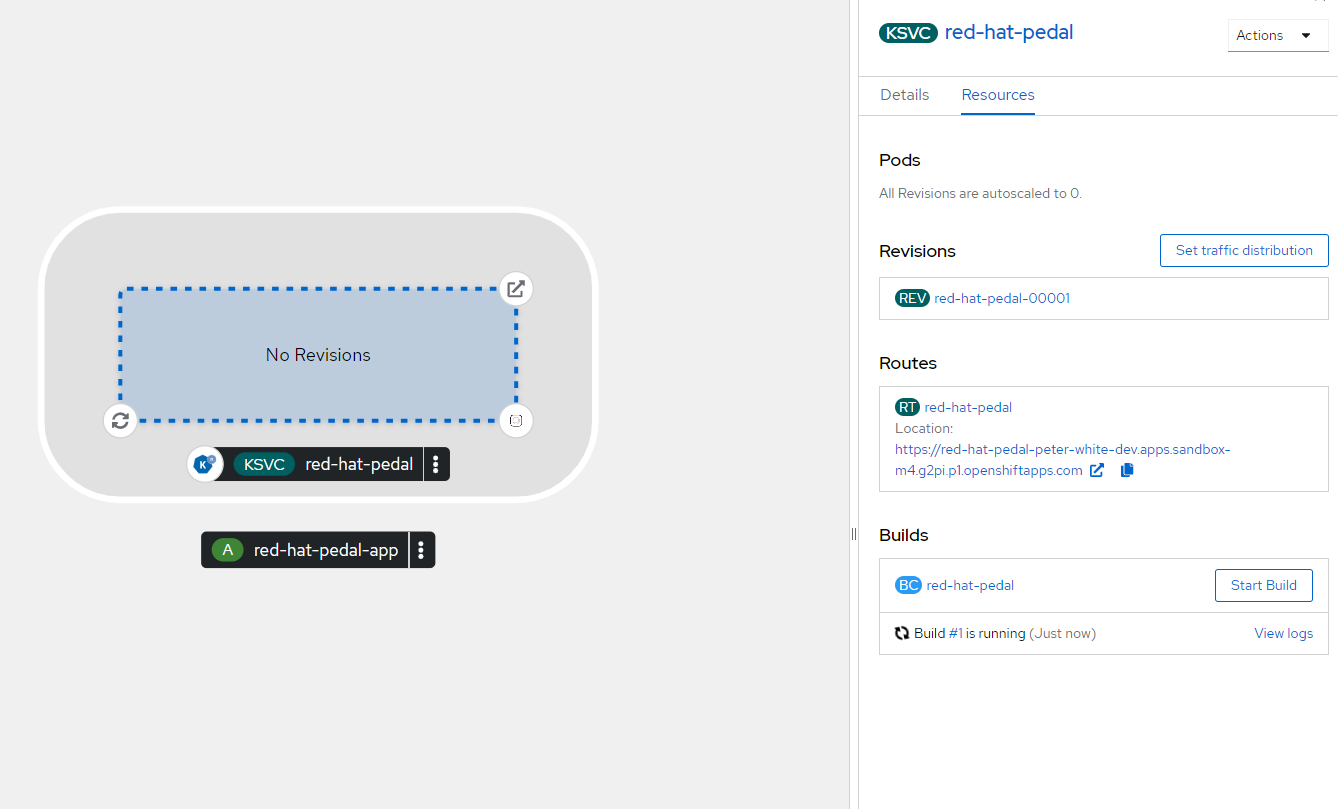
Figure 3. The running Pedal application.
Database creation
Pedal uses two databases: a PostgreSQL database for users and a SQL Server database for employees. Both databases need to be replicated on OpenShift. For this demonstration, you’ll use Argo CD to facilitate continuous deployment.
To effectively integrate Argo CD with your databases, creating and maintaining appropriate manifests that define the desired state of the database components is necessary. These manifests are typically stored in a version control system like GitHub. When you synchronize an application with Argo CD, this tool helps ensure that all the necessary Kubernetes objects for your databases are present and in the correct state on the target cluster. This process is central to how Argo CD operates, as it constantly monitors and adjusts the state of the cluster to match what’s defined in your manifests.
These manifests aren’t just scripts for building databases. Rather, they define the entire lifecycle and characteristics of the database in the Kubernetes environment — including how the databases should be configured and run. For instance, they can specify the necessary deployment configurations, persistent volume claims, services, and other Kubernetes resources.
When Argo CD syncs an application, it examines these files and ensures that every defined object is correctly instantiated and configured on the cluster. This process effectively leads to the creation of the database: It’s a result of these objects being correctly applied and managed, not a direct build process by Argo CD.
In most scenarios, managing databases via Argo CD requires a set of five different manifest files. Each file serves a specific purpose in defining the various aspects of the database deployment and operation. This approach ensures that the databases are deployed as intended and allows for version-controlled, systematic updates and modifications, enhancing the reliability and consistency of database deployments in Kubernetes environments.
Argo CD’s ability to continuously reconcile the actual state of the cluster with the desired state defined in these manifests makes it an effective tool for managing complex deployments, including databases.
Secret credentials
This file holds the connection details for your database. The PostgreSQL file looks like this:
apiVersion: v1
kind: Secret
metadata:
name: postgres-secret
type: Opaque
data:
POSTGRES_DB: [base64_encoded_database]
POSTGRES_USER: [base64_encoded_user]
POSTGRES_PASSWORD: [base64_encoded_password]ConfigMap
The ConfigMap in Kubernetes serves a specific purpose in managing the configuration data for your application’s containers. For instance, when configuring a PostgreSQL database, a ConfigMap file is used to store non-sensitive information necessary for creating and operating the database. This file typically contains configuration details such as database names, user names, and other settings required for the database to function correctly that aren’t confidential.
However, it’s important to understand the distinction between ConfigMaps and Secrets, as developers often face the question of when to use one over the other. The key difference lies in the kind of data they’re intended to store and manage. ConfigMaps are designed for storing non-sensitive configuration data. This can include information like database configuration, application settings, or other data that doesn’t include credentials or confidential details.
On the other hand, Secrets are used specifically for managing sensitive information. This includes data such as passwords, tokens, or keys. In the context of a PostgreSQL database, you should store credentials like the database password in a Secret rather than a ConfigMap. Secrets ensure that sensitive data is stored and transmitted securely within the Kubernetes cluster. They provide mechanisms to encode the data and restrict its access, making it a more secure option for confidential information.
In summary, while a ConfigMap is suitable for storing general configuration data for your PostgreSQL database, store any sensitive data, particularly credentials, in a Secret. Understanding and applying this distinction is crucial in maintaining both the functionality and the security of applications deployed in a Kubernetes environment.
In this instance, you’ll use the ConfigMap. For the PostgreSQL database, it looks like this:
apiVersion: v1
kind: ConfigMap
metadata:
name: postgres-config
data:
init.sql: |
-- Your SQL create script goes herePersistent volume claim
In configuring a PostgreSQL database in OpenShift, it’s important to clarify the role of various configuration files and resources. The statement about specifying the type of database, its size, and other configurations pertains more to the database’s deployment and service configuration than a PersistentVolumeClaim (PVC).
A PVC in OpenShift specifically manages storage requirements. A user initiates it as a storage request, devoid of specific details regarding database type, capacity, or operational configurations. Instead, the PVC allocates and attaches a certain amount of storage space from the available PersistentVolumes (PVs) to a container. The PostgreSQL database can then use this storage for storing data, but the PVC itself doesn’t define the database’s characteristics or behavior.
For configuring aspects like the type of database (for example, PostgreSQL), its size in terms of computing resources, and other settings, you would typically use a combination of other Kubernetes/OpenShift resources. These include DeploymentConfigs or Deployments, which define how the PostgreSQL container should be run, including the version of PostgreSQL, the environment variables, and other operational parameters.
A Service would define how to expose the database to other parts of your application or external users. Additionally, you might use ConfigMaps and Secrets for non-sensitive and sensitive configurations, such as database names, user names, passwords, and so on.
Hence, while the PVC is crucial for the storage aspect, the actual details about the database’s configuration, type, and operational parameters are specified through other resources and configuration files within the Kubernetes/OpenShift environment when setting up PostgreSQL on OpenShift.
For the PostgreSQL database, the PVC looks like this:
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: postgres-pvc
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 10GiExposing service
This ensures accessibility to the database from various pods within your application. For PostgreSQL, it appears as follows:
apiVersion: v1
kind: Service
metadata:
name: postgres
spec:
ports:
- port: 5432
selector:
app: postgres
type: ClusterIPStatefulSet
The StatefulSet file is the largest file, and it uses the other files to help direct OpenShift on database creation. For PostgreSQL, it looks like this:
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: postgres
spec:
selector:
matchLabels:
app: postgres
serviceName: "postgres"
replicas: 1
template:
metadata:
labels:
app: postgres
spec:
containers:
- name: postgres
image: postgres:latest
ports:
- containerPort: 5432
envFrom:
- secretRef:
name: postgres-secret
env:
- name: PGDATA
value: /var/lib/postgresql/data/pgdata
volumeMounts:
- mountPath: /var/lib/postgresql/data
name: postgres-storage
- mountPath: /docker-entrypoint-initdb.d/init.sql
name: init-script
subPath: init.sql
volumes:
- name: postgres-storage
persistentVolumeClaim:
claimName: postgres-pvc
- name: init-script
configMap:
name: postgres-config
items:
- key: init.sql
path: init.sqlBy placing these YAML files in your Git repository, you enable the automatic creation of databases you need for the application. Note, though, that SQL Server doesn’t automatically kick off create scripts on launch, so you need to start these manually or write a custom script for doing so.
Install Argo CD
To install Argo CD on OpenShift, switch to the Administrator perspective on the OpenShift console. Navigate to Operators → OperatorHub.
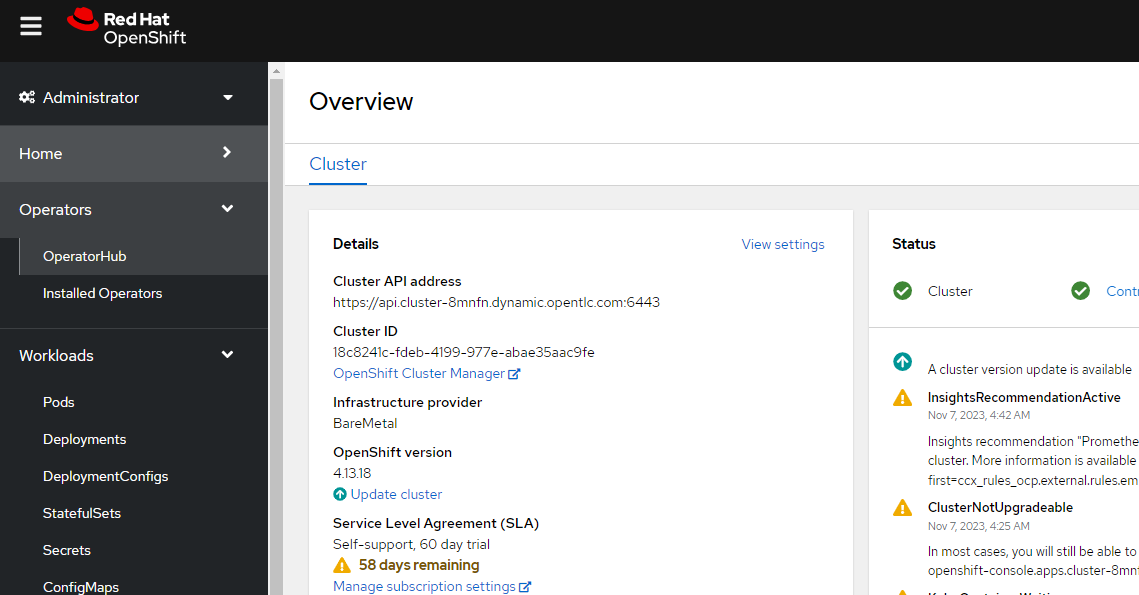
Figure. 4. Accessing the OperatorHub from the OpenShift console.
Search for “GitOps” look for the OpenShift GitOps operator, and click on it.
Then, click Install and follow the on-screen instructions to install OpenShift GitOpsOperator.
After installing Argo CD onto your OpenShift cluster, you can configure it for your deployment needs. Navigate to Installed Operators → Red Hat OpenShift GitOps to configure and create an Argo CD instance.
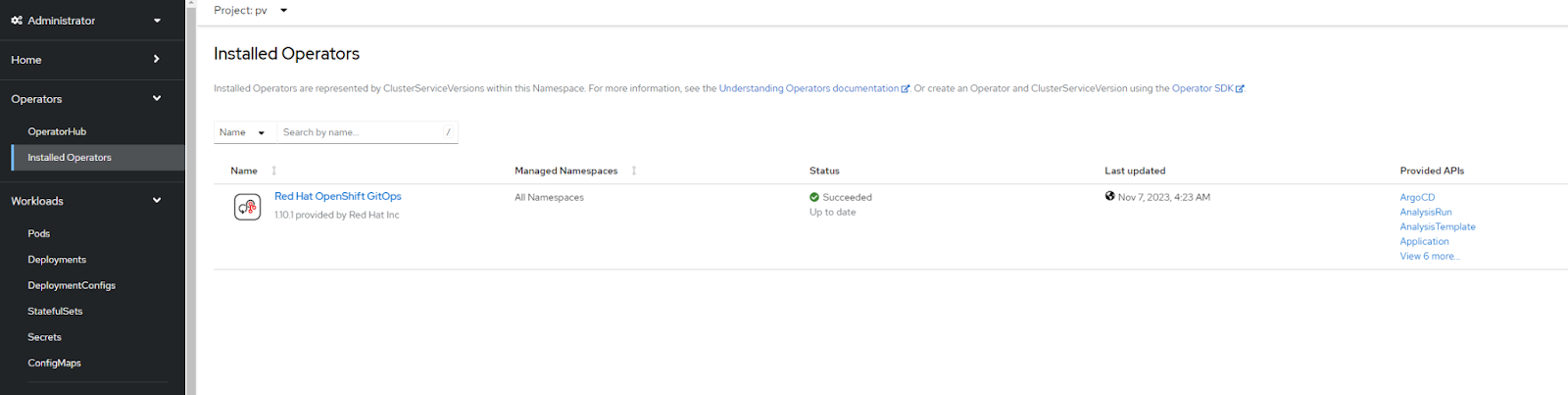
Figure 5. The Installed Operators page.
To configure your Argo CD instance, follow the instructions.
Register your cluster
If you’re using an ArgoCD instance that isn’t installed on the same cluster as the operator, you must follow a few extra steps. To connect an external Argo CD instance with an OpenShift cluster, you need first to obtain your kubeconfig file. This file is essential for authenticating and interacting with the cluster. If your instance is on the same cluster, you can ignore this next section.
OpenShift allows you to download this file directly from the web console. After logging into the OpenShift web console, go to your user profile and find the option to copy the login command. This will likely include a display showing a token and a command-line snippet with a --token flag.
While you can’t download the kubeconfig file directly from the console, you can use it to configure your local kubeconfig.
Next, use the OpenShift command-line interface (CLI) (oc) to set up your kubeconfig file. Run
oc login --token=your-token --server=your-server-url to populate the kubeconfig file with the correct context. Doing so will automatically overwrite your local kubeconfig file (typically located at ~/.kube/config) with the proper information.
To register your cluster, you must install the Argo CD CLI tool. For Windows, download the appropriate executable from the Argo CD’s GitHub releases page. Once downloaded, either add it to your PATH or keep track of where you’ve saved the executable so you can run it from the command line.
Next, register your OpenShift cluster with Argo CD using the following command, replacing <context-name> with the context you want to add from your kubeconfig file:
argocd cluster add <context-name> --kubeconfig path/to/your/kubeconfig This context should now correspond to your OpenShift cluster. Running this command will add your OpenShift cluster to Argo CD, letting you deploy and manage applications.
Move YAML files to Git
Argo CD employs a GitOps approach to application delivery, which necessitates storing YAML manifests in a Git repository. This strategy ensures a single source of truth for the desired application state, enabling version control, full audit trails, and collaborative change management.
When you update your application’s configuration in Git, Argo CD automatically detects these changes and synchronizes the Kubernetes resources’ state to match the manifest’s declared state. This process enhances security and transparency by tracking changes and their history in Git, simplifying rollbacks and review processes.
When managing applications in OpenShift, it’s often necessary to extract YAML definitions for resources such as DeploymentConfigs, Services, or Routes. These definitions serve multiple purposes, including replication of the environment elsewhere or for backup requirements.
To retrieve the YAML for a DeploymentConfig using the OpenShift web console, follow these steps.
From the main menu in the OpenShift web console, navigate to the Workloads section. In the context of OpenShift version 4.14 and later, where DeploymentConfigs have been deprecated, you should focus on Deployments. Select Deployments from the drop-down options to view all the deployments in the currently selected project. This view replaces the older DeploymentConfigs view and aligns with standard Kubernetes practices, offering more streamlined and updated deployment management.
If there’s no existing deployment in your project, you can initiate a new one by clicking Create Deployment. This process allows you to specify the settings and configurations for your new deployment according to your application’s requirements. The transition from DeploymentConfigs to Deployments in OpenShift 4.14 and beyond reflects a shift towards a more Kubernetes-native approach, ensuring better compatibility and more efficient deployment processes.
Creating a new Deployment allows you to define crucial elements like the container image, replica count, resource limits, and other deployment-specific settings. This capability strengthens the management of your applications within OpenShift, making them more robust, scalable, and aligned with modern Kubernetes practices.

Figure 6. Creating a DeploymentConfig.
Click the name of the Deployment you’re interested in. This action will take you to the overview page for that Deployment.
On the Deployment page, navigate to the YAML tab at the top.
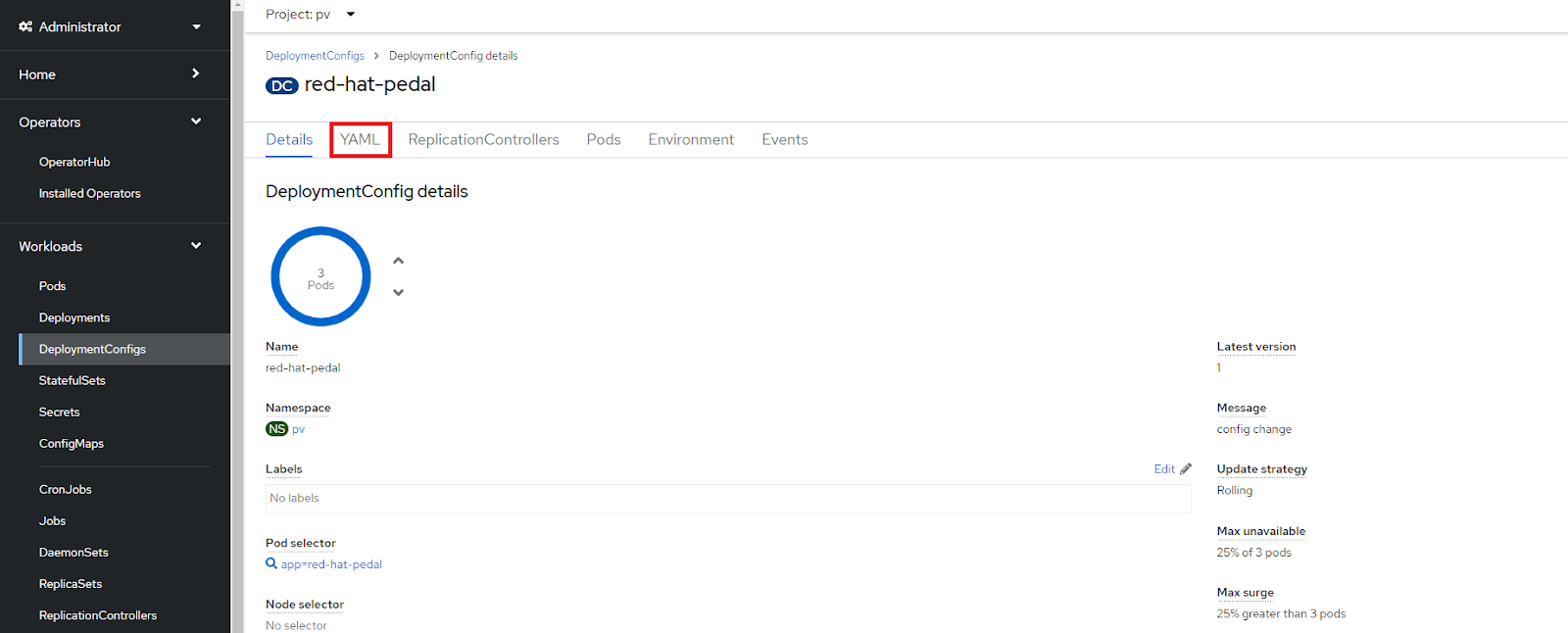
Figure 7. Accessing the DeploymentConfig’s YAML.
From here, you can copy the YAML content directly from the editor. This YAML represents the configuration of your Deployment in OpenShift. Create a new file with this text to integrate it into your GitOps workflow.
Now, you must incorporate the YAML file into your existing GitHub project for use with Argo CD. Start by creating a new directory in your local clone of the GitHub repository dedicated to storing your OpenShift resource configurations. You might name this directory according to the resource type, such as config.
Save the copied YAML content into a new file within this directory. The file name should reflect the application or resource it represents, like deployment.yaml. This naming convention helps maintain clarity and organization in your repository.
After saving the file, push the commit to your GitHub repository using git push. This action updates your repository with the latest Deployment configuration, making it available for Argo CD to access and deploy.
By following these steps, you establish a systematic approach to managing the desired state of your OpenShift application through version control. This is a fundamental aspect of the GitOps methodology, ensuring that Argo CD continuously reconciles the state of your cluster with the configurations stored in your Git repository. It’s a practice that creates a robust and reliable single source of truth for your application’s infrastructure and configuration.
Repeat these steps for other resource configurations, like Service YAML and Routes YAML, to comprehensively manage your application’s deployment in OpenShift through GitOps. This process streamlines deployment and enhances consistency and traceability across your application’s lifecycle.
Create a new Argo CD project
To create a new project in Argo CD, you’ll use the Argo CD CLI, which provides a fast and efficient way to manage your projects and applications.
After logging in to your Argo CD instance, you can create a new project using the command argocd proj create followed by the desired project name. For example, issuing the command argocd proj create my-project in your terminal will generate a project called my-project within Argo CD.
This new project acts as a container that can group various applications, allowing you to manage access control, resource quotas, and project-specific policies under a unified umbrella.
Once you’ve created the project, you can configure it by defining source repositories, destinations, and permissions. Do so using subsequent CLI commands or by editing the project’s configuration through the Argo CD web UI. This project setup is essential to organizing and scaling your deployment management with Argo CD's GitOps capabilities.
Create a new Argo CD application
Creating a new Argo CD application is possible through both the CLI and the web interface. For this tutorial, use the web interface.
Upon logging into the Argo CD instance, you’ll see a blank interface with no applications. The first step to creating an Argo CD application is to connect your Git repository. Select Settings from the left-hand sidebar. Click Repositories and paste a link to your repository.
Now, return to the Argo CD homepage and +New App.
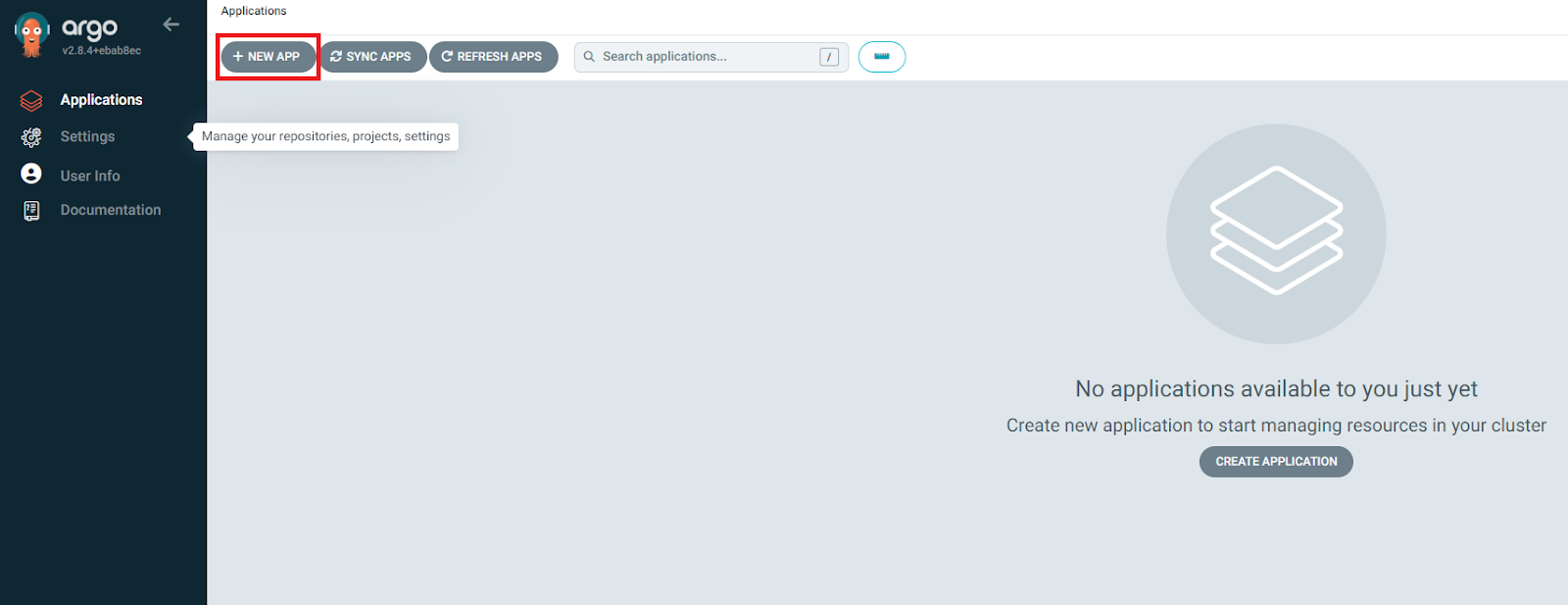
Figure 8. Creating a new Argo CD application.
You’ll see a form, shown below, to enter details about the application. Give the application a name, and in the project name field, input the name of the Argo CD project created earlier. You can set the sync policy to automatic to ensure that your Argo CD project stays up to date, but leave it as manual for now.
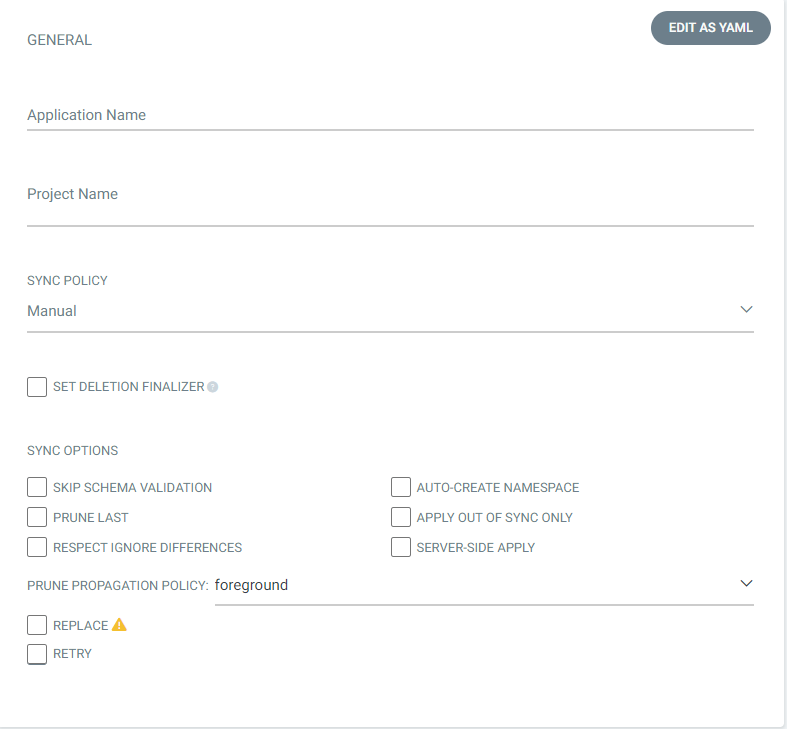
Figure 9. Adding Argo CD application details.
Below this form, you’ll see a field for adding a link to your repository. In the Repository URL field, link to the main project. In the Path field, link to the Config folder in the repository where you stored the OpenShift YAML files earlier.
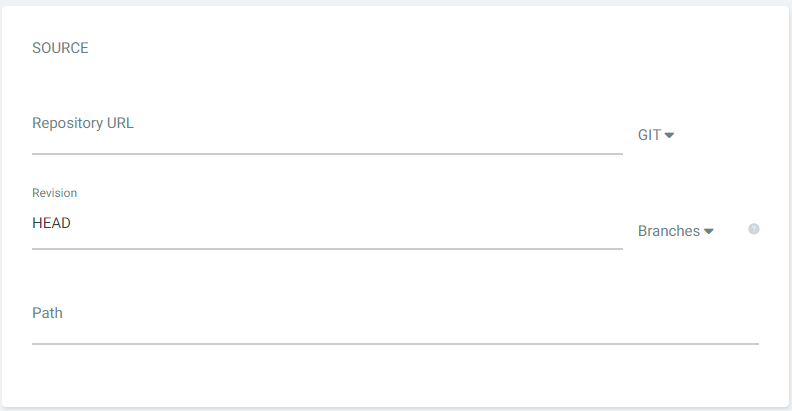
Figure 10. Adding your Git repository.
Finally, fill out the Destination form. This details the cluster where you want to deploy the application.
Here, you can use the project namespace you defined in OpenShift, but you also need to enter the cluster URL. You can find it by clicking on your username at the top right of the console and selecting Copy Login Command from the drop-down. Note that you may need to log in again.
You’ll see a login command display, including a token. There should also be an option to display the token From here, you should see the ClusterURL listed in the information given. Copy and paste it into the ClusterURL field.
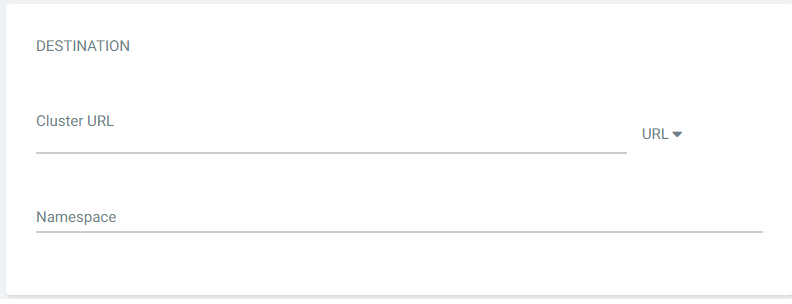
Figure 10. The Destination form.
Click Create to complete the application.
This action will redirect you to the home screen, where your application becomes visible. Press Sync at the top of the screen to sync your application to the Git repository. If completed correctly, you’ll receive an indication confirming the successful sync.

Figure 11. Syncing the application.
Conclusion
Modernizing a traditional Java application like Pedal unveils the transformative potential of containerization and orchestration. Red Hat OpenShift, boasting a robust platform, becomes the optimal stage for legacy applications, integrating seamlessly with Kubernetes for scalable, resilient, and easily manageable deployments. Transitioning from monolithic architecture to microservices in containers revitalizes these legacy applications, preparing them for continuous integration and deployment.
Argo CD, introduced in this modernization, employs a GitOps approach to declare Pedal’s desired state in Git repositories. It diligently monitors these repositories to ensure synchronization with the actual state in the OpenShift cluster. This alignment is crucial for maintaining consistency and reliability amid changes. Argo CD’s automated synchronization safeguards against human errors, streamlining updates, reducing downtime, and enhancing the overall development lifecycle.
The synergy between OpenShift’s container orchestration and Argo CD’s continuous delivery modernizes and maintains Pedal applications efficiently. This collaboration offers agility, scalability, and resilience — essential attributes for high-performing apps in the modern software environment.
