Continue.dev is an innovative plug-in for Visual Studio Code designed to enhance the productivity of developers by enabling connections to a variety of providers and models. Recognizing the unique needs of certain projects, there are instances where an isolated environment is essential, particularly when there’s a requirement to deploy a fine-tuned base model that aligns more closely with a team’s specific coding practices.
Red Hat OpenShift AI
Red Hat OpenShift AI offers a robust solution for such scenarios, providing a secure and isolated platform that supports model serving in environments with stringent connectivity restrictions. It leverages the power of service mesh and Knative to offer inference APIs, ensuring seamless integration and operation within these specialized setups. This allows teams to maintain high levels of accuracy in code generation while operating within the confines of their tailored development ecosystem. OpenShift AI thus represents a critical tool for teams seeking to harness the full potential of AI in their development processes while adhering to their particular operational requirements.
KServe
KServe is a powerful Kubernetes Custom Resource Definition called InferenceService that facilitates machine learning model serving across various frameworks. Designed to address production inference scenarios, it offers a high-performance, highly abstracted interface for popular ML frameworks such as TensorFlow, XGBoost, Scikit-Learn, PyTorch, and ONNX.
Leveraging Red Hat OpenShift Serverless and Red Hat OpenShift Service Mesh, KServe simplifies the complexities of auto-scaling, networking, health checks, and service configuration (Figure 1). It brings cutting-edge service features to ML deployments, such as GPU auto-scaling, scale-to-zero capabilities, traffic monitoring, and canary releases. KServe presents a straightforward, pluggable, and comprehensive solution for production ML serving, encompassing prediction, preprocessing, postprocessing, and explainability.
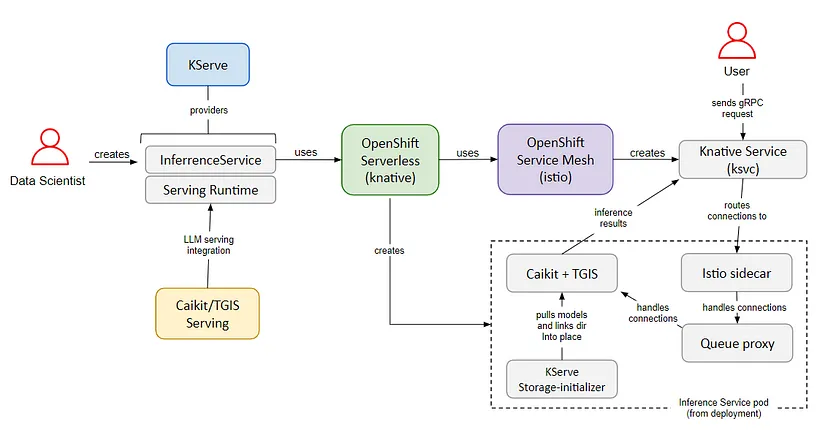
Caikit
On the other hand, the Caikit toolkit offers developer-friendly APIs for model management with standard gRPC and HTTP interfaces for querying base models, channeling requests to the TGIS inference service. TGIS, an early branch of the Hugging Face text generation inference service toolkit, enhances LLM performance with features like continuous batching, dynamic batching, tensor parallelism (model sharding), and support for PyTorch 2 compilation.
NVIDIA GPU Operator
The NVIDIA GPU Operator automates the management of software components required for configuring and utilizing NVIDIA GPUs within OpenShift. This includes driver containers, device plug-ins, and the DCGM metrics exporter, which integrates with OpenShift’s Prometheus monitoring to provide insights into GPU metrics such as memory utilization and streaming multiprocessor (SM) utilization.
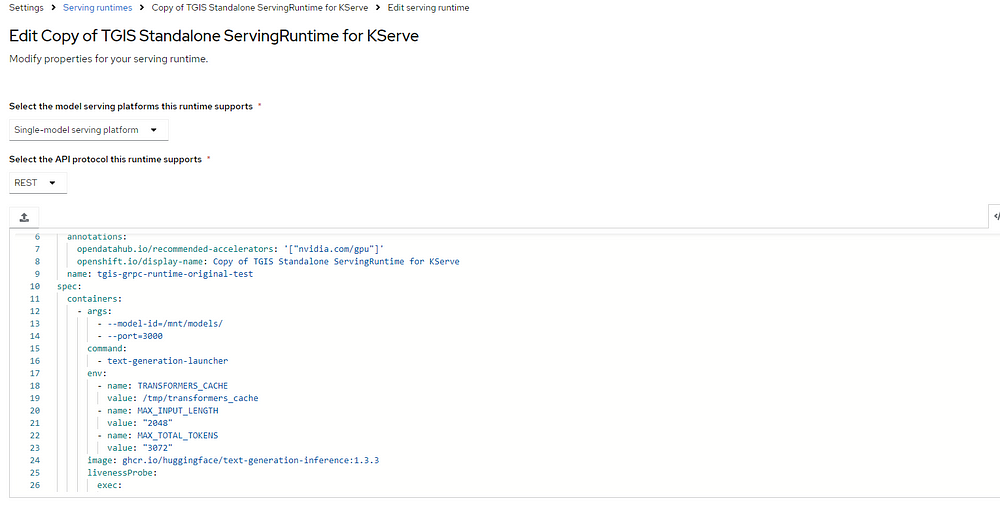
To effectively implement the TGI serving, it is essential to leverage a specialized serving runtime tailored to meet the specific needs of the application. This can be achieved by importing a custom serving runtime that accompanies the product (Figure 2). The next step involves customizing this runtime to align with the HuggingFace TGI image specifications.
Additionally, it is important to ensure that the runtime is configured to support a RESTful type of inference API, which will facilitate seamless interaction and communication with the service.
The core spec of YAML spec is as follows:
spec: containers: - args: - --model-id=/mnt/models/ - --port=3000 command: - text-generation-launcher env: - name: TRANSFORMERS_CACHE value: /tmp/transformers_cache - name: MAX_INPUT_LENGTH value: "1024" - name: MAX_TOTAL_TOKENS value: "2048" image: ghcr.io/huggingface/text-generation-inference:1.3.3 livenessProbe: exec: command: - curl - localhost:3000/health initialDelaySeconds: 5 name: kserve-container ports: - containerPort: 3000 name: h2c protocol: TCP readinessProbe: exec command: - curl - localhost:3000/health initialDelaySeconds: 5 multiModel: false supportedModelFormats: - autoSelect: true name: pytorch
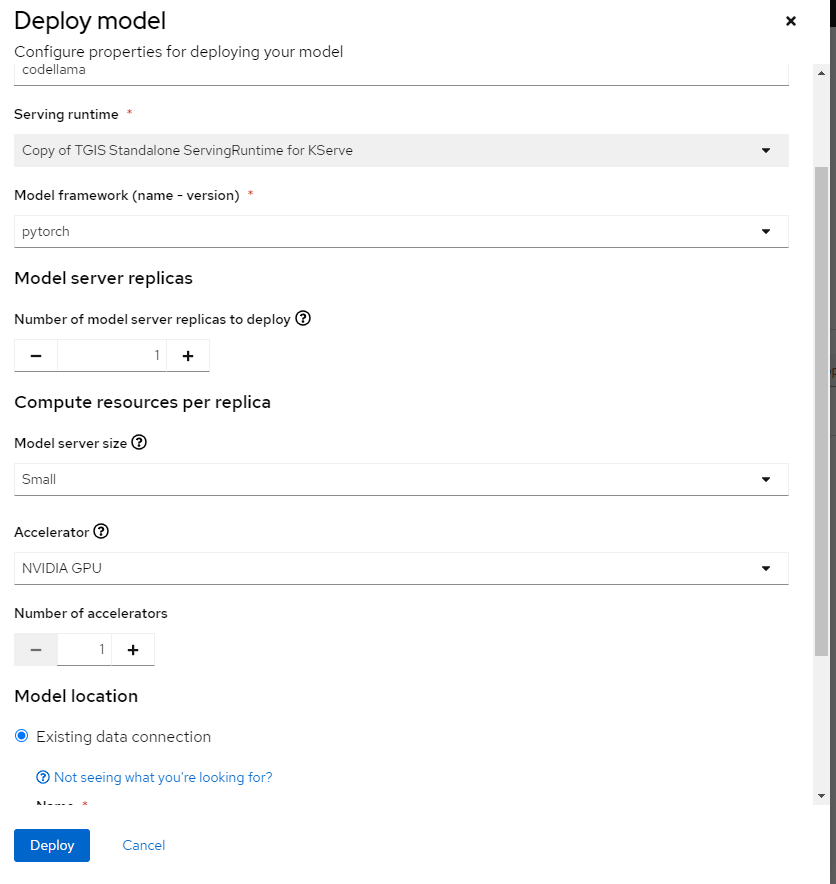
Then create a model deploy directly in the AI project scope with imported model data in S3, as shown in Figure 3. The serving in OpenShift AI will copy the model files in the init stage and set up the disconnected serving runtime.
For a few minutes, you'll see the pod running with several restarts (due to the resources, most likely). See Figure 4.

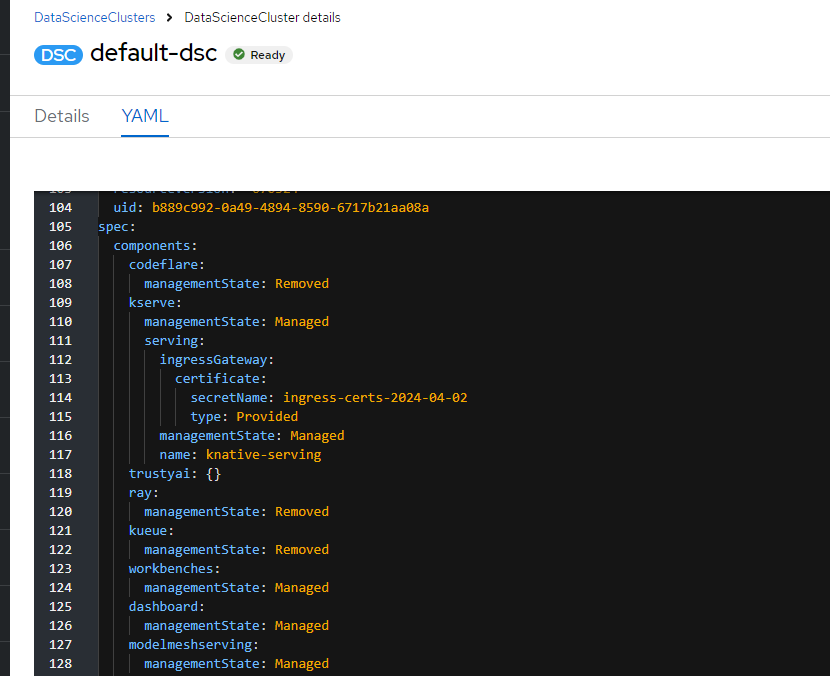
Also note that the TLS certificate is self-signed by default; we have to replace it with a correctly signed certificate or the client cannot proceed with the request to the server. By placing the TLS secret in the ods-operator project, we can point to it with a config in the Data Science Cluster custom resource. See Figure 5.
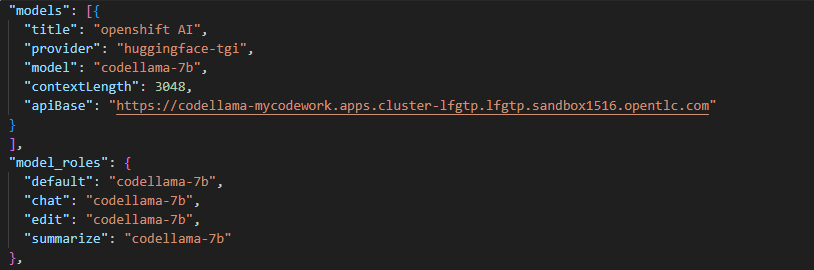
Then we can configure the Continue’s config.json (Figure 6) to point to the newly setup model serving entry point by Service Mesh.
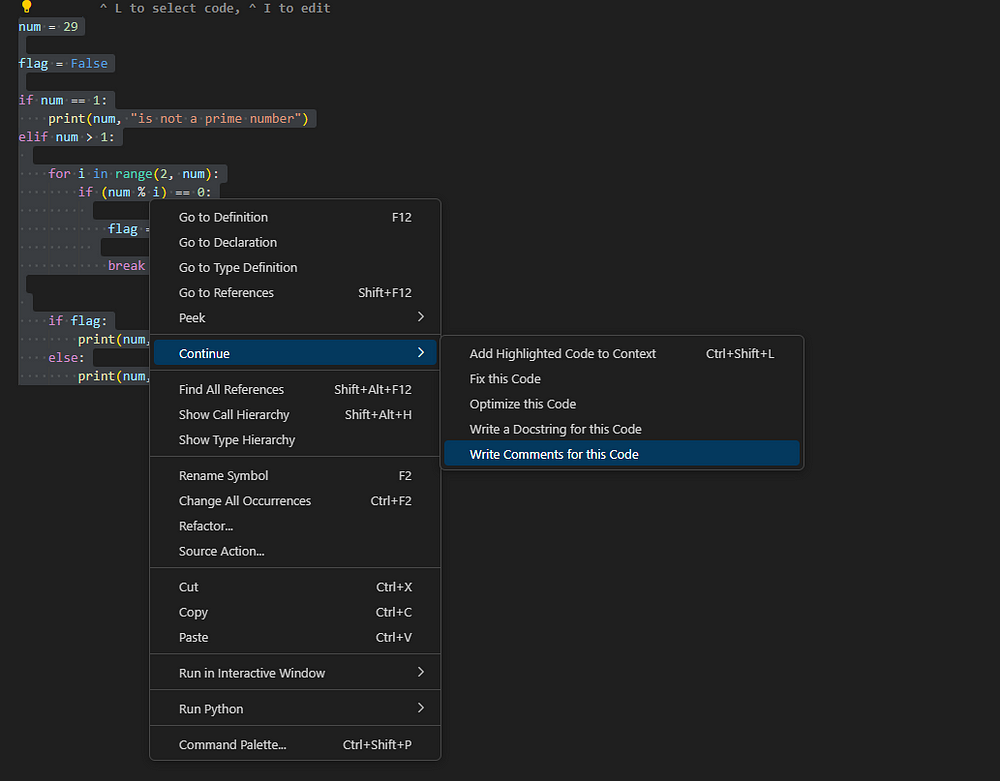
Then test some of the features in VS Code with Continue (see Figure 7).
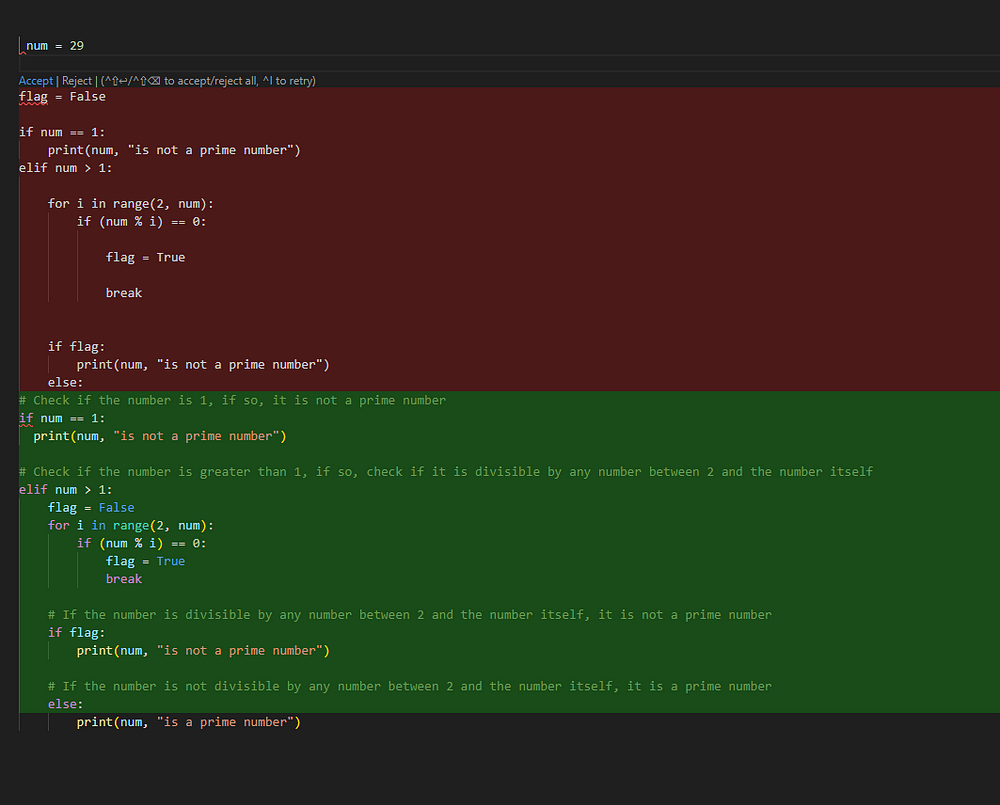
Comments are generated as expected, as shown in Figure 8.
Conclusion
In response to the need for secure and private model serving in industries where data sensitivity is paramount, such as finance and manufacturing, it is crucial to establish a robust and trusted model serving runtime within a private data center. This approach ensures that sensitive code and data are not exposed to the vulnerabilities associated with the internet.
To facilitate seamless integration and maintain industry standards, the runtime environment should be compatible with open-source model serving protocols. By doing so, organizations can leverage the benefits of advanced analytics and machine learning while upholding strict data governance and security policies. Implementing such a solution allows these industries to harness the power of their data without compromising on confidentiality or compliance requirements.
