One challenge of managing models in production environments with Red Hat OpenShift AI and KServe is the dependency on S3-compatible storage. When serving models using KServe in OpenShift AI, users must deploy S3-compatible storage somewhere accessible in their cluster and then upload their model to an S3 bucket. Managing models through S3 creates new challenges for traditional operations teams deploying production services. Teams may need to create new processes to promote model artifacts from development/test environments.
OpenShift AI 2.14 enabled the ability to serve models directly from a container using KServe's ModelCar capabilities, and OpenShift AI 2.16 has added the ability to deploy a ModelCar image from the OpenShift AI dashboard. This article demonstrates how to build and deploy models with ModelCar containers in OpenShift AI and discusses the pros and cons.
How to build a ModelCar container
ModelCar container requirements are quite simple; model files must be located in a /models folder of the container. The container requires no additional packages or files.
Developers can simply copy the model files from their local machine into the container. However, in our example we will use a two-stage build process to download a model from HuggingFace and then copy the files into a clean container.
We will use the Granite 3.1 2b Instruct model in our example.
Step 1: Create a file
Begin by creating a file called download_model.py with a simple script that uses the huggingface-hub package to download the model as follows:
from huggingface_hub import snapshot_download
# Specify the Hugging Face repository containing the model
model_repo = "ibm-granite/granite-3.1-2b-instruct"
snapshot_download(
repo_id=model_repo,
local_dir="/models",
allow_patterns=["*.safetensors", "*.json", "*.txt"],
)The script uses the snapshot_download function to download the Granite model to the /models folder.
Step 2: The two-stage build
This two-stage build process allows us to minimize the content in the final container used in our deployment. While the difference in the container size of the final image compared to the original container is minimal relative to the size of large language models (LLMs), we reduce the potentially vulnerable packages needed to run in our production environment by excluding these additional resources.
- Stage 1: In the first stage of the Containerfile, we will install the
huggingface-hubpackage, copy our script into the container. Then execute it to download the model files from HuggingFace. - Stage 2: We will copy the model files from the first stage into the second stage.
Now let's create a Containerfile with our two-stage build as follows:
FROM registry.access.redhat.com/ubi9/python-311:latest as base
USER root
RUN pip install huggingface-hub
# Download the model file from hugging face
COPY download_model.py .
RUN python download_model.py
# Final image containing only the essential model files
FROM registry.access.redhat.com/ubi9/ubi-micro:9.4
# Copy the model files from the base container
COPY --from=base /models /models
USER 1001Step 3: Build the container
To build the container, we will use podman to build the image in our local environment:
podman build . -t modelcar-example:latest --platform linux/amd64Once the image has been built, you can push the image to a container registry, such as quay.io:
podman push modelcar-example:latest quay.io/<your-registry>/modelcar-example:latestOur ModelCar image is now ready to be deployed in an OpenShift AI cluster.
Deploy a model server with a ModelCar container
We will use the vLLM instance that ships with OpenShift AI. To deploy the model from the OpenShift AI dashboard, you must be running OpenShift 2.16 or newer. Your cluster will also require an accelerated computing infrastructure GPU to successfully run the model. An NVIDIA A10 Tensor Core GPU is a great budget option if you are provisioning a new node in your cluster.
- To begin, create a new project in the OpenShift AI dashboard where you plan to deploy your model.
- Next you will need to choose the Select single-model option in the Single-model serving platform section.
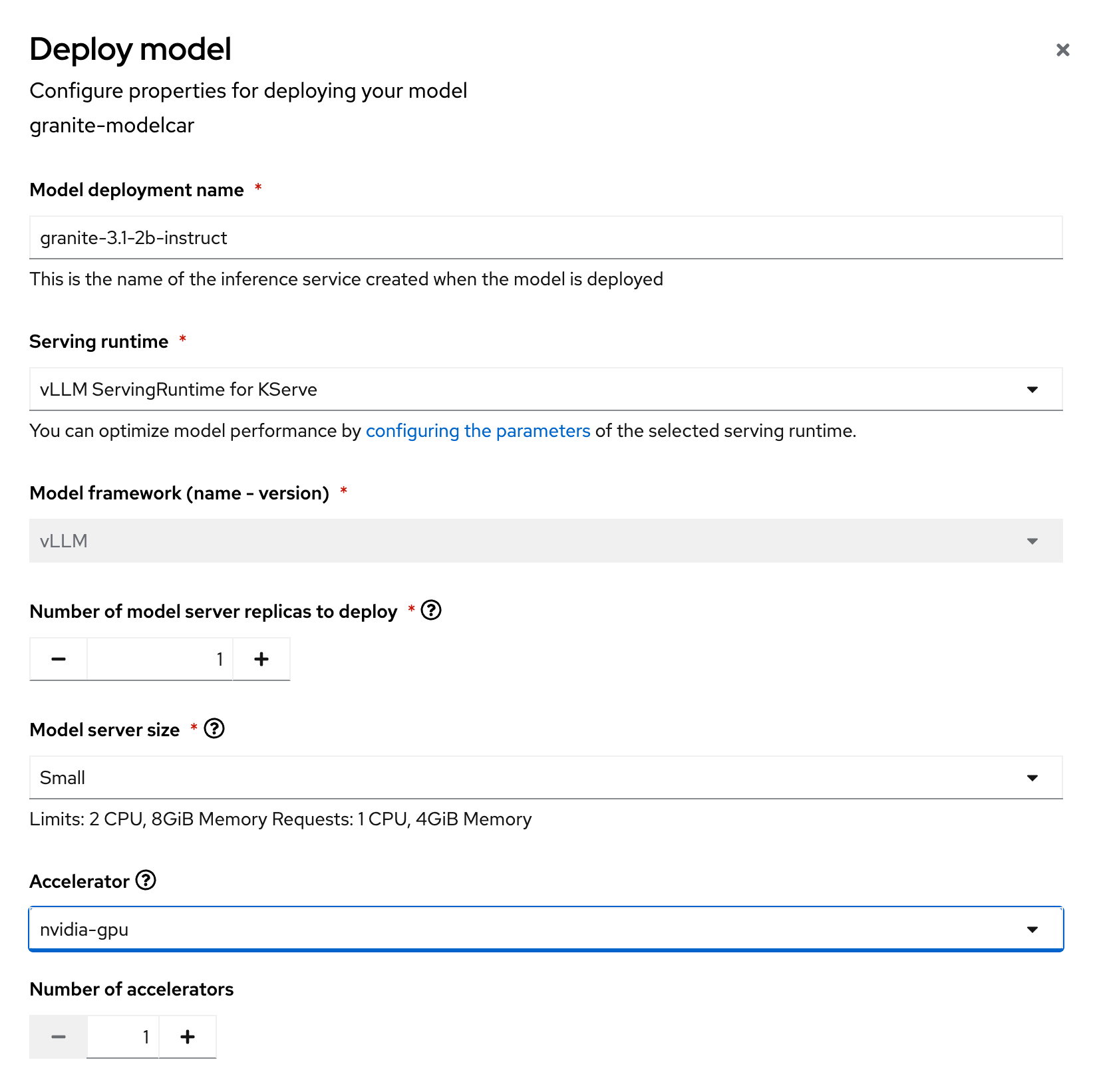
Click the option to Deploy model (Figure 1).
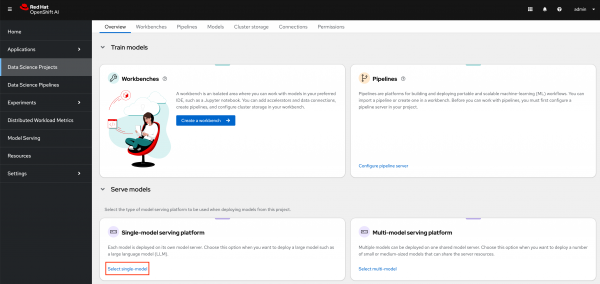
Figure 1: Select single model serving. On the Deploy model page shown in Figure 2, fill in the following options:
Model deployment name: granite-3.1-2b-instruct Serving runtime: vLLM ServingRuntime for KServe Number of model server replicas to deploy: 1 Model server size: Small Accelerator: nvidia-gpu Number of accelerators: 1 Model route: Checked Token authentication: Unchecked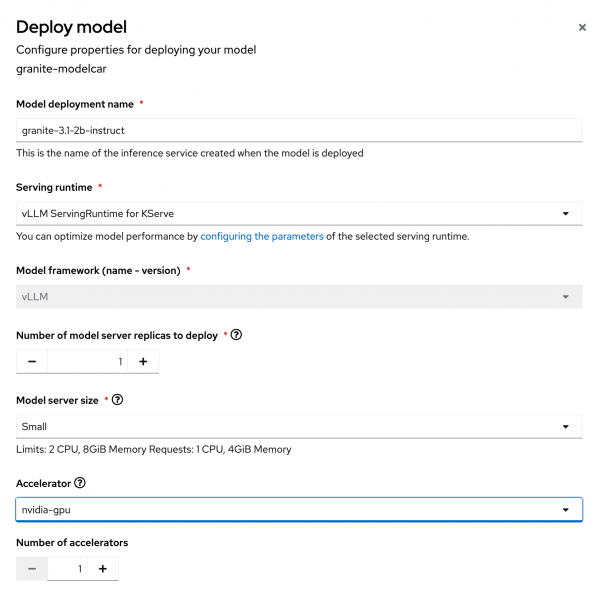
Figure 2: Deploy model form with options filled out. - Your accelerator name might be slightly different depending on what your administrator named it when they configured the GPU capabilities in OpenShift AI.
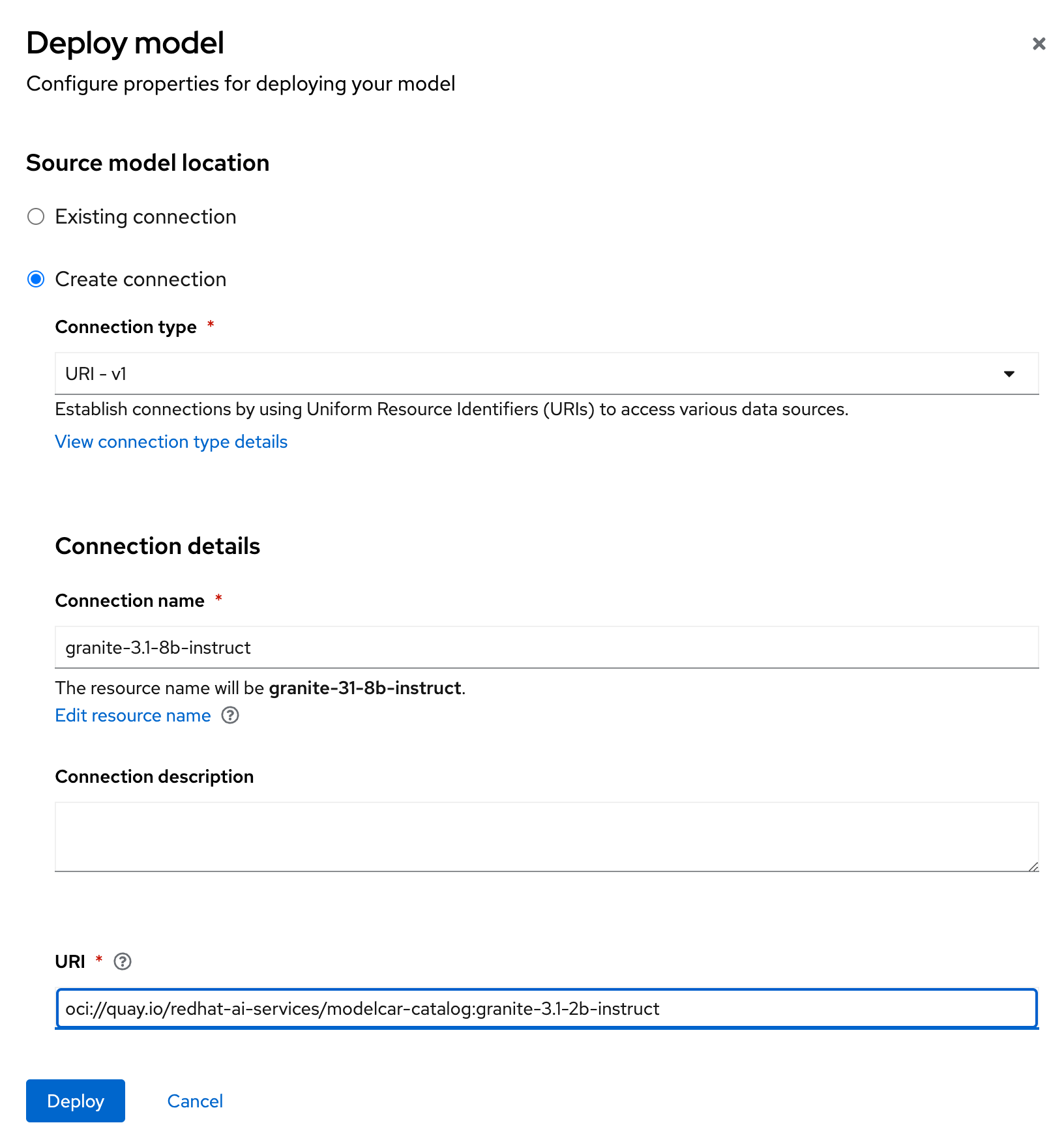
- When you get to the source model location section (Figure 3), choose the Create connection option.
- Set the option type to UIR - v1.
For the connection details, use the following:
Connection name: granite-3.1-8b-instruct URI: oci://quay.io/redhat-ai-services/modelcar-catalog:granite-3.1-2b-instruct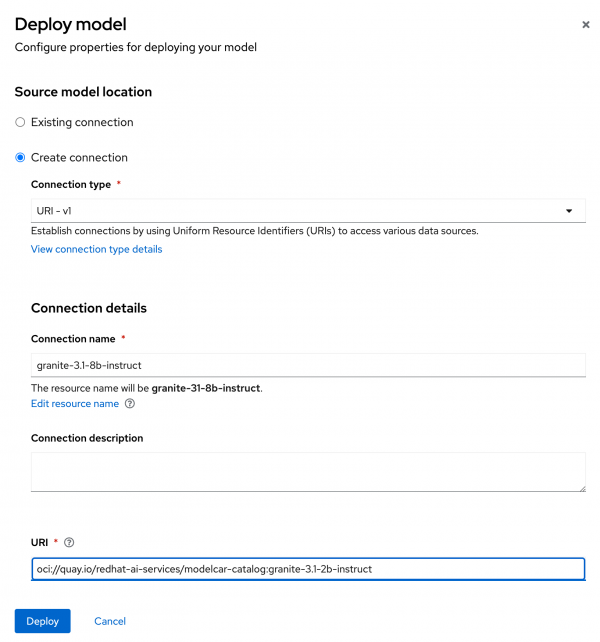
Figure 3: Source model location. - Feel free to replace the image URI with the image you built and published in the previous section.
- Once everything has been updated, click Deploy.
- A new pod should be created in your namespace to deploy the model. It may take several minutes to successfully pull the image for the first time, but on subsequent startups, the container image should be pre-cached on the node to make the startup much faster.
By default, KServe creates a KNative Serving object which has a default timeout of 10 minutes. If your model has not successfully deployed in that time, KNative will automatically back the deployment off. The first time you deploy the LLM on the node it may take longer than 10 minutes to deploy. You can change the default timeout behavior by adding the following annotation to the
predictorportion of theInferenceServicefrom the OpenShift AI dashboard:apiVersion: serving.kserve.io/v1beta1 kind: InferenceService metadata: name: granite-31-2b-instruct spec: predictor: annotations: serving.knative.dev/progress-deadline: 30m- After the pod successfully starts, you can now access your LLM by locating the URL in the OpenShift AI dashboard.
ModelCar containers pros and cons
ModelCar containers standardize the way an organization delivers models between environments. However, working with ModelCar images can introduce challenges. Let's delve into the pros and cons.
Pros
- ModelCar presents a great opportunity to standardize the way in which an organization delivers models between environments by allowing them to leverage the same technologies and automation they likely already have for managing container images. Making the models as portable as any other container image while also reducing the risk of a file not getting copied from one environment to another brings all of the same benefits that we love about container images for application management.
- Once cached on a node, the process of starting a vLLM instance can also be significantly faster than the model startup time from S3-compatible storage.
Cons
- Working with ModelCar images can introduce new challenges due to the size of the LLMs and the corresponding image. A small LLM such as the Granite 2B model creates a container about 5Gb while a medium size model such as the Granite 8B will be about 15Gb. Very large models such as Llama 3.1 405b will be about 900Gb in size, making it very challenging to manage as a container image.
- Building large containers can be challenging with the large amount of resources required. Pulling very large container images can quickly overwhelm a node's local cache.
- Some of the challenges related to model size may become less pronounced over time as new technologies help bridge the gap. Tools such as KitOps attempt to package models into container images more intelligently, and other improvements are added to Kubernetes to improve pulling large container images.
Learn more
In this article, you learned the benefits of ModelCar containers and how to build a ModelCar container image and deploy it with OpenShift AI. To find more patterns and pre-built ModelCar images, take a look at the Red Hat AI Services ModelCar Catalog repo on GitHub and the ModelCar Catalog registry on Quay.
Try Red Hat OpenShift AI and explore what's new.
Last updated: February 12, 2025