Nowadays, everybody talks about artificial intelligence (AI) and machine learning (ML). They have the potential to become essential technologies that drive business growth, foster innovation, and enable you to stand out amongst colleagues and competitors. As C-level executives, software developers, and business analysts, it's crucial to understand what AI/ML models are, how they work, and how algorithms like random forest and linear regression can transform your organization.
Let’s break it down in simple terms, avoiding the technical complexities while focusing on business impact. This article is a follow-up of the previous article, The road to AI: Fundamentals, which provided a high-level introduction to the concept of AI and marked the beginning of this series. This article will focus solely on describing AI/ML models.
This article is for readers with various technical backgrounds. I’ll highlight sections that delve deeper into technical details. If you’re primarily interested in understanding the broader concepts, feel free to skip these sections. Unless, of course, you’re curious and want to dive deeper. For example, the "Key algorithms" section is fairly technical, intended for readers with a strong technical background to grasp the details of commonly used algorithms.
What are AI/ML models?
AI/ML models are systems designed to learn from data. They identify patterns, make predictions, and automate decision-making processes. These models help businesses forecast trends, optimize operations, enhance customer experiences, and drive innovation.
Explained in simple terms:
- AI is the broader concept of machines that can perform tasks that require human intelligence. These tasks can be (hard-) coded like graph database queries and Spark pipelines. Or, to trigger discussions, what about advanced if-else statements?
- ML is a branch of AI that allows machines to learn from data and get better over time, without relying on explicit rules programmed by humans. Instead of being manually coded, ML models are trained on large datasets, functioning like a black box that adapts and improves through experience.
- Deep learning (DL) is a branch of ML that uses neural networks (see the "A closer look at Neural Networks" section) to automatically learn features and patterns from large amounts of data. It excels at handling complex tasks like image recognition, natural language processing, and speech recognition by progressively learning hierarchical representations of data.
- LLMs are a subset of deep learning, which falls under ML. It is specifically trained on vast amounts of text data to predict and generate human-like text (i.e., predictions). It operates as an "autocomplete on steroids," leveraging deep neural networks not to just finish sentences but also generate coherent paragraphs, answer complex questions, and understand nuanced context. By recognizing patterns in language, LLMs enable advanced applications in natural language processing, from chatbots to content creation.
Applications of LLMs:- Text generation (e.g., ChatGPT, Mistral or DeepSeek)
- Language translation
- Sentiment analysis
- Text summarization
- Code generation
- Knowledge retrieval (e.g., retrieval-augmented generation, or RAG)
For example, fraud detection is a practical example of how AI, ML, and advanced techniques like DL and LLMs fit together. We will use the following visualization in Figure 1.
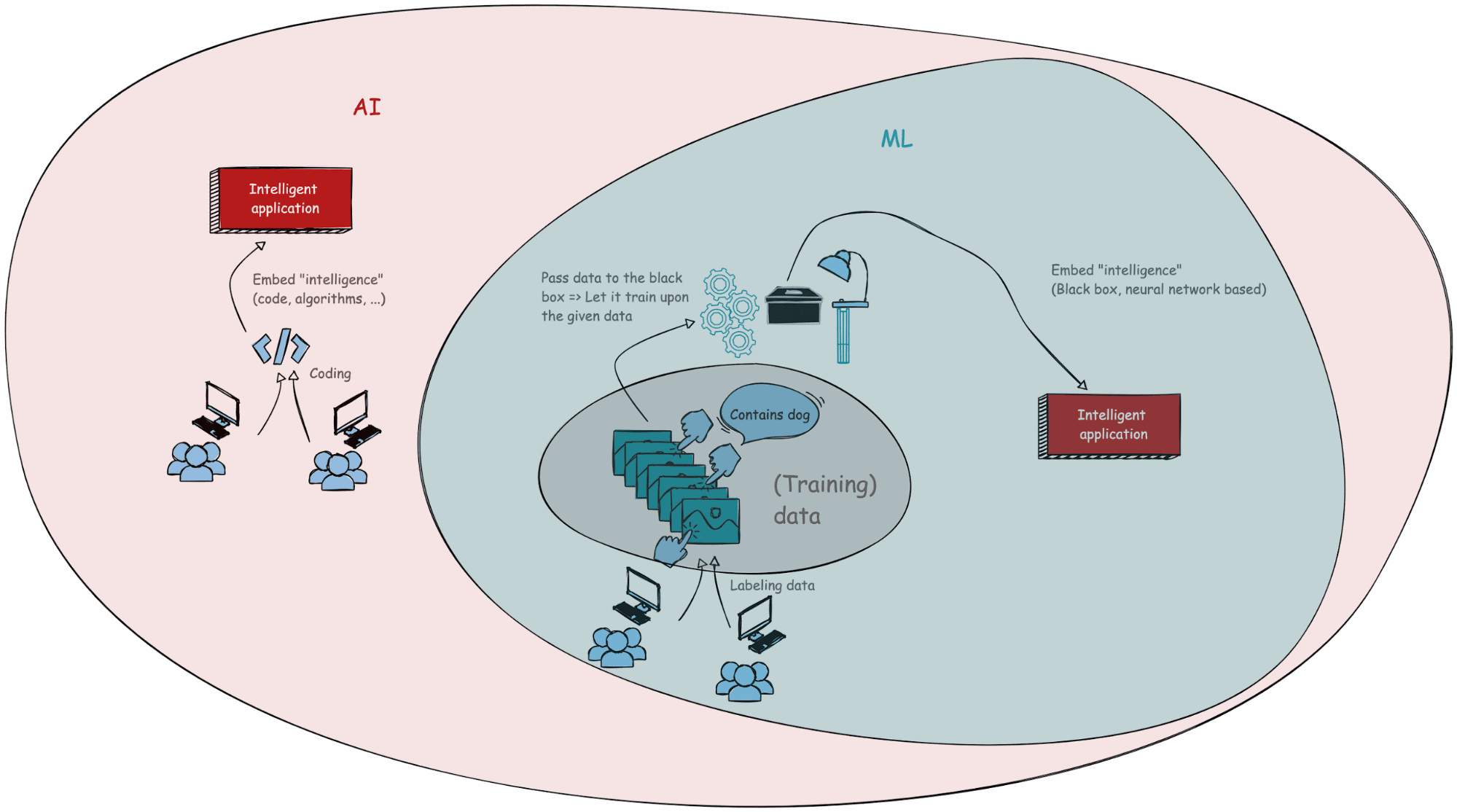
Suppose we’re building an application to detect fraudulent transactions. Initially, we might hard-code logic to identify fraudulent patterns (e.g., using advanced coding or graph database queries). Where would you put advanced if-else code structures? Is this AI as well? While this approach mimics human decision-making, qualifying it as AI, it remains rigid and limited in adaptability and flexibility.
To make the system smarter, we transition to ML. We start by gathering a labeled dataset of transactions marked as “fraudulent” or “correct.” Note that from this step onward, we need to possess a tremendous amount of data, or big data sets. This dataset is split into a training set (usually 80%) to teach the model and a test set (20%) to evaluate its accuracy. The model undergoes training by processing transactions in the training set, predicting outcomes (fraudulent or correct), and adjusting until its accuracy meets a predefined threshold (e.g., 95%). Once validated using the test data, the model is deployed within the application.
Now, we only talked about ML, we didn’t make the distinction between DL and LLMs. Well, that distinction is mainly made on the structure (i.e., algorithm) of the black box (more on this in the upcoming sections). ML encompasses a wide range of algorithms, including linear regression, decision trees, and more. DL, a subset of ML, uses neural networks to model complex patterns. LLMs are a specialized type of DL model designed for NLP tasks.
The choice of this technique/algorithm mainly depends on the nature and complexity of the data. If you're predicting the amount of ice that you need to have in stock for an ice cream shop, and the only parameters you take into account are temperature and day of the week, linear regression will be sufficient for you. If you need to train the black box model of image recognition, you will need to make use of neural networks (Figure 2).

For the remainder of this article, I will use the name “AI models,” but if you read the previous article, you'll realize that it mostly focuses on ML models. We can go even further than just machine learning, and tackle deep learning (i.e., with supervised, unsupervised and reinforcement learning), but that would take us too far past this article. We’ll deal with it in a later one, so stay tuned.
How AI models work
As described more thoroughly in the previously mentioned article, the process of building an AI model typically follows these steps:
- Data collection: Gathering historical data from your business processes (e.g., sales data, customer behavior, or sensor data).
- Training the model: Feeding the data into a machine learning algorithm to learn patterns and relationships.
- Prediction or decision-making: The trained model is then used (i.e., deployed) to predict future outcomes or automate decisions.
For example, an AI model could analyze past sales data and predict next quarter's sales or recommend personalized offers to your customers based on their purchasing habits.
When we think about AI and machine learning, it's common to hear about neural networks as the leading technology, but there are numerous other techniques that play a vital role. These include algorithms such as random forests, decision trees, linear regression, and k-means clustering, each offering unique advantages for different applications.
In the next "Key algorithms" section, I’ll dive into some of these methods in more detail.
Key algorithms
In this discussion on key algorithms, I'll dive into some of these methods in more detail. The key algorithms are random forest, linear regression, k-nearest neighbors, and neural networks.
Note:
If the content of this section becomes too technical, feel free to skip ahead, as this section is intended to provide deeper insight for those interested.
A closer look at random forest
One of the popular algorithms in machine learning is random forest. Let’s briefly explore how this works and why it matters for business.
Imagine you’re making an important decision, and you ask multiple experts for their advice instead of relying on a single person. Each expert gives you their opinion, and you then make a decision based on the collective input. This is essentially what the random forest algorithm does.
Here’s how it works:
- Trees: It builds many decision trees like flowcharts that split data based on certain features (e.g., Is the customer a repeat buyer?).
- Forest: Each tree gives a prediction, and the random forest aggregates the results to give the most accurate prediction.
Why is this important? Random forest is powerful because it reduces the risk of overfitting (i.e., creating models too specific to the data) and works well with both structured and unstructured data, making it versatile for real-world business problems such as fraud detection, customer segmentation, and churn prediction.
The strength of random forest comes from the fact that its individual decision trees are mostly independent of each other. Even if some trees make mistakes, the majority will produce correct predictions, ensuring that the overall result is more accurate and reliable.
A practical example of random forest
A random forest is like a team of decision-makers. Imagine you’re trying to decide what movie to watch, and you ask ten friends (each representing a decision tree) for their recommendations. Each friend considers different factors (like genre, length, and actors) to make their own choice. After hearing all their suggestions, you go with the movie that most of them recommend. This is essentially how random forests work (Figure 3).
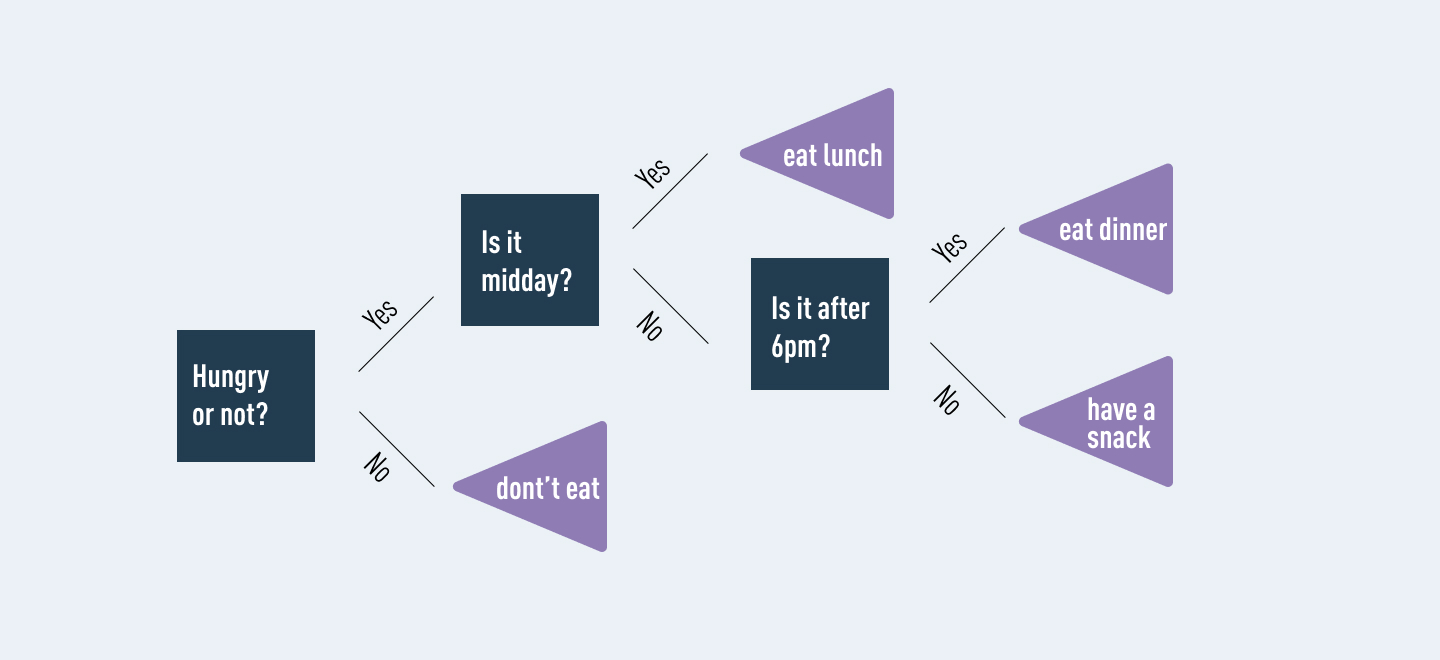
Let’s say you’re predicting whether someone will like a movie based on three factors:
- Genre (Action, Comedy, Drama)
- Length (short, medium, long)
- Actors (famous or unknown)
Each decision tree in the random forest looks at different combinations of these factors and makes its own prediction (like or dislike). The random forest combines the predictions of all trees and chooses the most common result (e.g., 7 out of 10 trees say "like," so the final answer is "like").
In short, a random forest uses many decision trees to make a better, more reliable prediction.
A closer look at linear regression
Linear regression in AI is a basic yet powerful technique used to predict a continuous output based on one or more input features. It assumes a linear relationship between the input (i.e., independent variables) and the output (i.e., dependent variable). The goal is to find the best-fitting line that minimizes the difference between the predicted and actual values.
2 practical examples of linear regression
Example 1
Imagine a company wants to predict the future revenue based on advertising spending. Using linear regression, the model takes historical data (advertising spend vs. revenue) and finds the relationship between the two. Once trained, it can predict revenue based on a new advertising budget, helping executives make data-driven decisions.
Example 2
We run an ice cream shop and collect data on factors like temperature, day of the week, holidays, seasons, and the amount of each flavor sold. Using linear regression, we can predict how much ice cream we'll sell in the coming week based on these factors (e.g., temperature). This can help us optimize our inventory and staffing, ensuring we don’t overstock or understaff for the upcoming days (Figure 4).
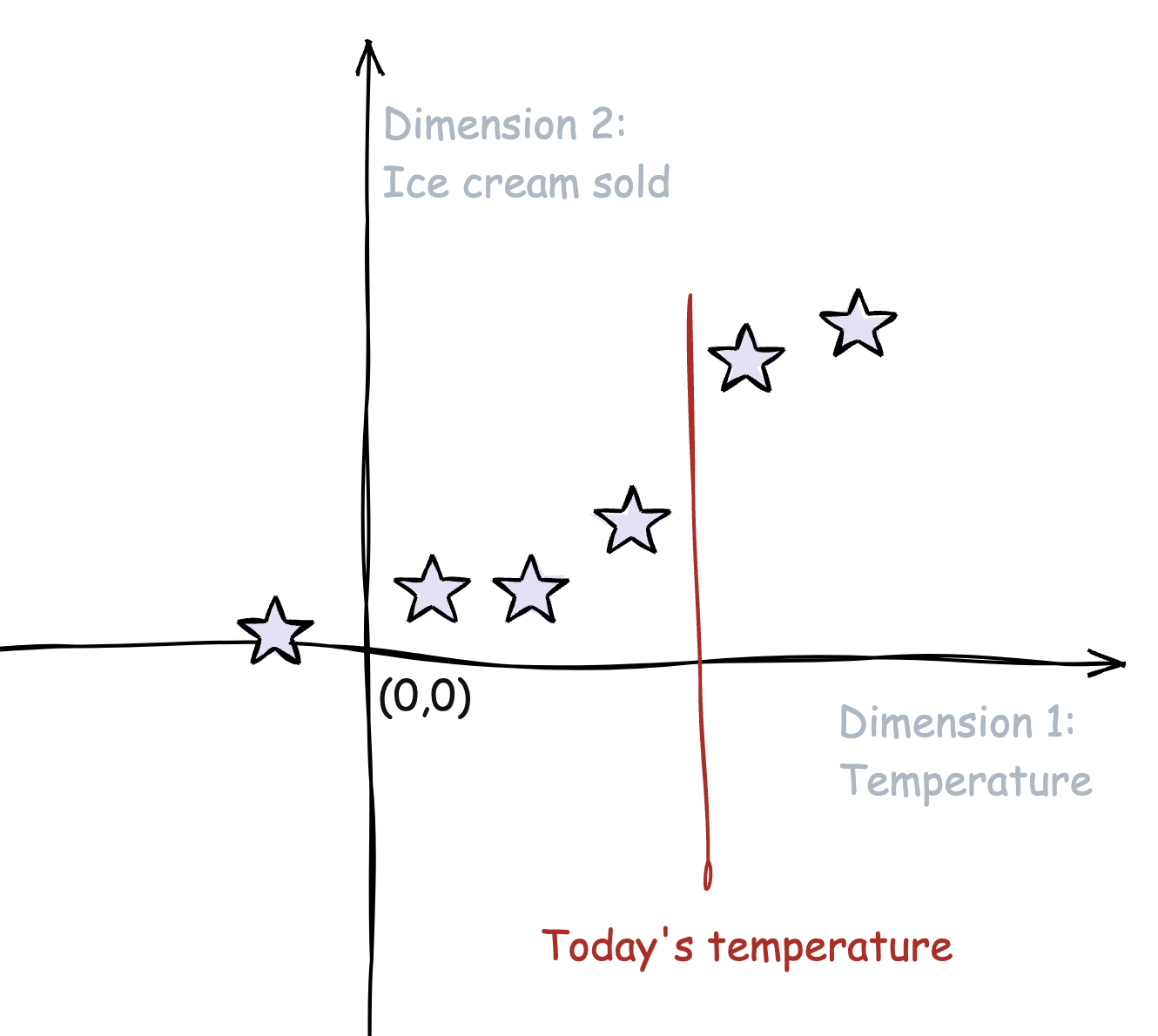
A closer look at k-nearest neighbors (K-NN)
The k-nearest neighbors (K-NN) is a simple yet powerful algorithm used in machine learning for classification and regression tasks. The idea behind K-NN is to predict the output for a new data point by looking at the "K" closest data points (neighbors) in the dataset. The algorithm assumes that similar data points will have similar outcomes, so it uses the majority vote (for classification) or the average (for regression) of the neighbors to make a prediction.
A practical example of K-NN
Suppose you run an online bookstore and have data on your customers, including their reading habits, favorite genres, and purchase history. If a new customer joins and provides their favorite genres and browsing behavior, K-NN can help recommend books by looking at the preferences of similar customers (their "neighbors"). If most of the nearest customers enjoy science fiction and recently purchased a popular sci-fi title, the algorithm might recommend that same book to the new customer (Figure 5).
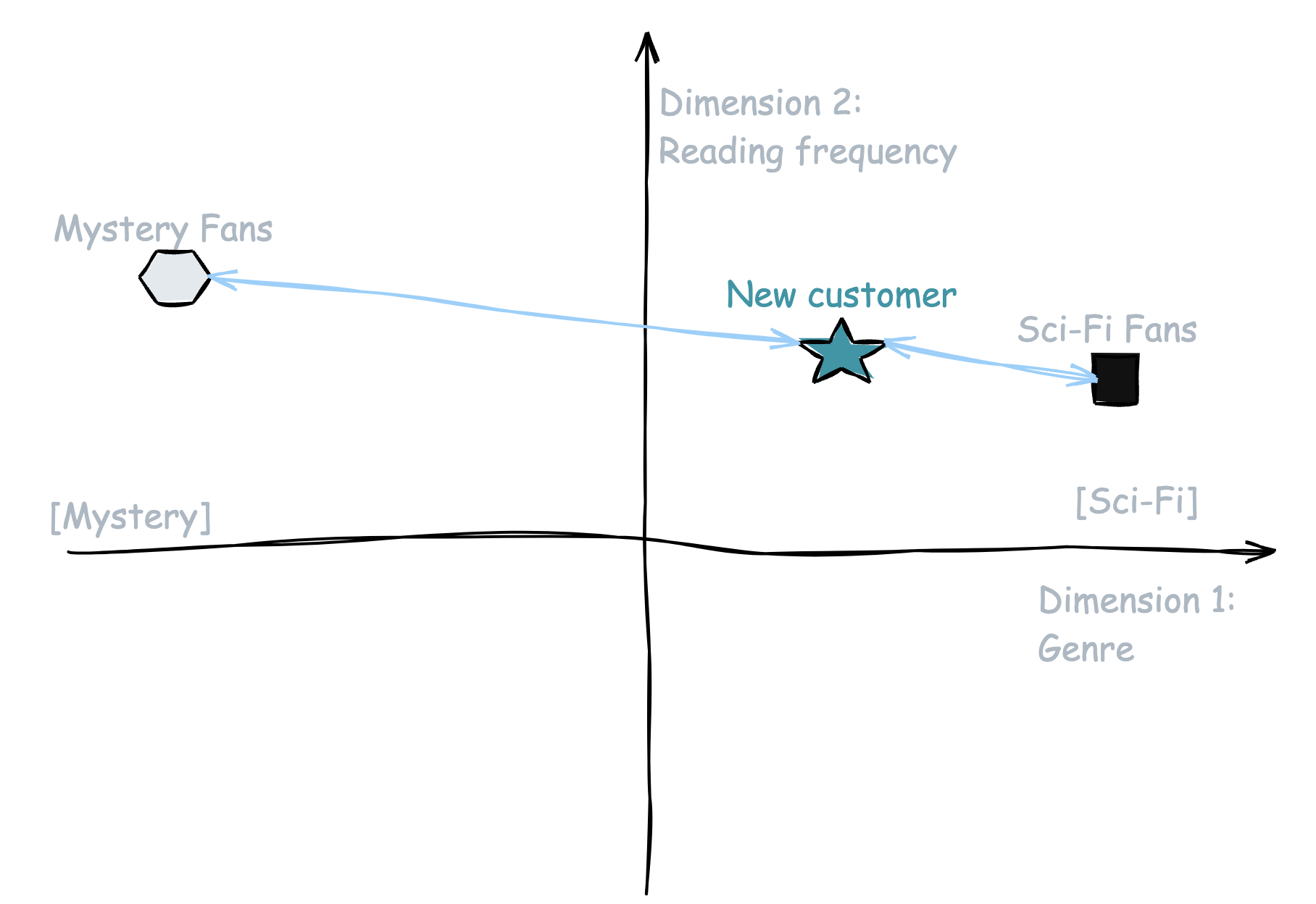
This algorithm is intuitive and easy to implement, but as datasets grow larger or become noisier, it can become less efficient and struggle to provide precise recommendations.
A closer look at neural networks
Neural networks are a class of machine learning models inspired by the human brain. They are made up of layers of interconnected units called neurons, or nodes, which process input data and learn patterns to make predictions or decisions. Neural networks are the foundation of many artificial intelligence applications, including image recognition, speech processing, and natural language understanding (Figure 6).
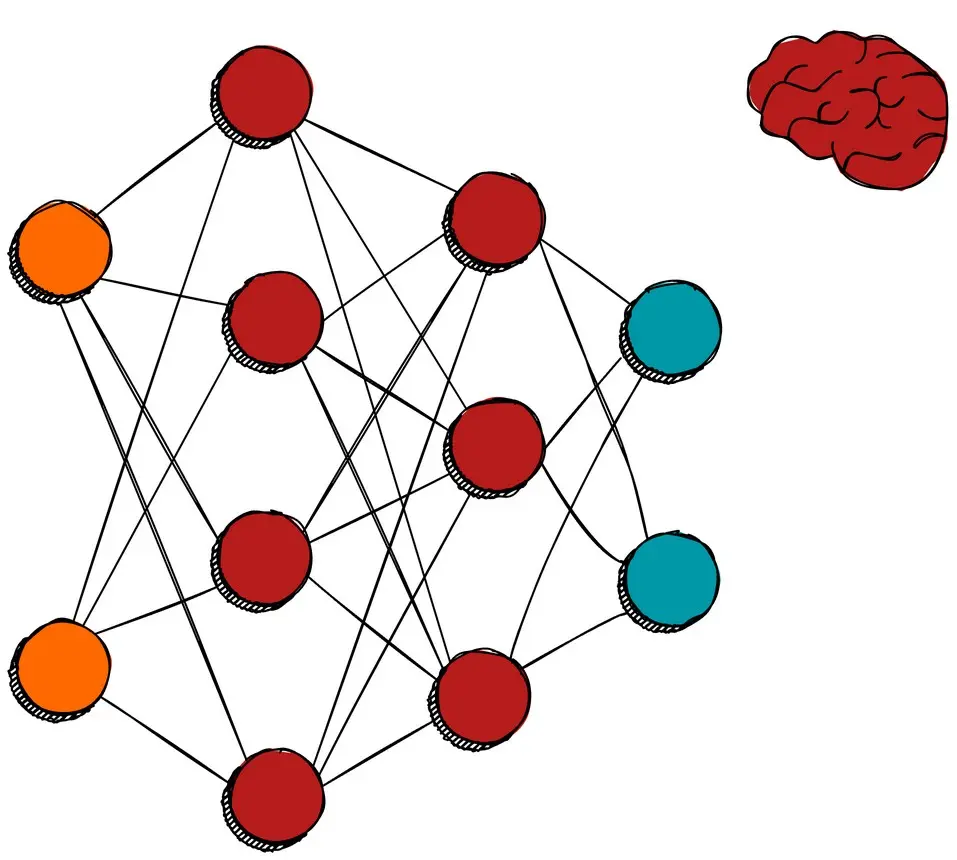
Key components of a neural network
- Neurons (nodes): Each neuron receives input, processes it, and passes the result to the next layer of the network. Neurons in a layer are connected to neurons in subsequent layers through weights.
- Layers:
- Input layer (orange neurons in Figure 6): This is the first layer that receives the raw data or features (e.g., pixels of an image, text, or sensor data).
- Hidden layers (red neurons in Figure 6): These layers lie between the input and output layers and perform complex computations. The term "deep learning" comes from networks with many hidden layers.
- Output layer (blue-green neurons in Figure 6): This layer provides the final result or prediction (e.g., class label, probability, or continuous value).
- Weights: Each connection between neurons has an associated weight, which adjusts during training. Weights determine the strength of the input and influence the output of the neuron.
- Bias: A bias term is added to the weighted sum of inputs to a neuron, helping the network fit the data better by shifting the activation function. Without a bias term, all the neural network’s decision boundaries would have to pass through the origin (zero), limiting the range of patterns it can learn—so bias acts like an intercept in a line equation, allowing the network to shift the decision boundary up or down and handle more complex data.
Activation functions: An activation function in a neural network decides whether a neuron should be activated or not, based on the information it receives. Think of it like a switch that turns on or off based on the input. It helps the network learn more complex patterns rather than just basic relationships by introducing non-linearity. ReLU is one of the most common activation functions.
ReLU can help the network ignore irrelevant information (i.e., negative values) and focus on useful patterns:
- If the input is positive, ReLU lets it pass through (e.g., input 5, output 5).
- If the input is negative or zero, ReLU turns it into 0 (e.g., input -3, output 0).
The following video demonstrates these components and explains in more detail.
How a neural network learns
Neural networks learn by adjusting their internal settings (weights and biases) to reduce the difference between their prediction and the actual result.
- Forward propagation: Data moves through the network, layer by layer, to make a prediction.
- Error calculation: The network checks how far the prediction is from the correct answer using a formula called a loss function.
- Back propagation: The network goes backward through its layers to adjust the weights, so future predictions are more accurate. This method is called gradient descent, which helps it learn step by step.
- Training: The network repeats this process many times until it becomes good enough at making predictions.
It's like trial and error. The network makes guesses, learns from its mistakes, and keeps improving.
Applications of neural networks:
- Image recognition: detecting objects in photos
- Speech recognition: virtual assistants like Siri
- Natural language processing: machine translation or chatbots
- Game playing: AlphaGo
- Medical diagnosis: detecting diseases from scans
A practical example of neural networks
Imagine we want to build a neural network that predicts whether an email is spam or not. The input could be features such as word count, presence of certain keywords, or the sender's address. The hidden layers will learn the relationships between these features (e.g., emails with certain words are more likely to be spam). Finally, the output layer will provide a probability of the email being spam.
Over time, as the model is trained on more and more data, the neural network gets better at identifying spam emails based on these hidden patterns in the data.
Base models versus instruct models
Instruct models are a specialized subset of Large Language Models (LLMs) that are fine-tuned specifically to follow user instructions more accurately than a general LLM (i.e., a base model). If a general LLM is like an all-purpose assistant able to chat about anything, an instruct model goes a step further. It’s trained to really listen to your prompts and shape its response according to your directives or goals.
Rather than just generating text loosely related to what you asked, instruct models pay closer attention to the format, style, and exact requirements you specify in your prompt. Think of it as the difference between a talented writer (a general LLM) who can produce engaging content, and a professional copywriter (an Instruct model) who not only writes well but also actively follows your brief, ensuring the message hits the right tone, structure, and key points.
Technical note (you can skip if you prefer not to go deep): Instruct models are created by fine-tuning an existing LLM with a special dataset of instructions and ideal responses, often curated and vetted by human experts. This process makes the model more instruction-aware, allowing it to respond with greater alignment to your specific goals.
Model distillation
Model distillation isn’t strictly an ML algorithm in its own right, but it operates like a specialized technique aimed at reducing a model’s computational footprint. It is a way to transfer knowledge from a large expert AI model (the teacher) into a smaller apprentice model (the student) so that it still performs well. This process helps retain performance while reducing computational and memory requirements. Think of it like having a senior chef (the teacher) who has spent years mastering many complex recipes, then teaching a junior chef (the student) the key techniques and shortcuts needed to make those dishes almost as well as the chef. The student model ends up simpler and faster, making it easier to run in everyday environments like phones or small devices.
A practical example of model distillation
Imagine you run a bakery and use a sophisticated AI tool to predict how much bread to bake each day. This tool is very accurate, but also very large and slow to use on a small in-store computer. Using distillation, you create a leaner version of this tool by having the simpler tool learn directly from the answers the bigger one provides. The smaller system quickly picks up the essential patterns (like which day's demand is higher) without needing the entire complex machinery. As a result, you keep the bakery running smoothly with timely predictions but without the heavy computing demands of the original model.
AI/ML in action
Let's consider a hypothetical scenario where a retail company uses AI/ML models.
- Customer segmentation: By using algorithms like random forest, the company can categorize its customers into different segments (e.g., high spenders, seasonal buyers) and offer targeted promotions.
- Inventory management: Using linear regression models, they can predict future demand based on historical sales data and optimize stock levels, reducing the risk of overstocking or stockouts.
- Personalized recommendations: Leveraging deep learning (neural networks), the retailer can recommend products to customers based on their browsing and purchase history, leading to higher sales and customer satisfaction.
Challenges of machine learning
One of the challenges of machine learning is the balance between deterministic and non-deterministic results. Deterministic models, like linear regression, always produce the same output for the same input, which makes them predictable and easy to interpret. In contrast, non-deterministic models, such as neural networks, can produce slightly different outputs even when trained on the same data due to factors like random initialization, stochastic optimization, and dropout layers.
Building a fraud detection system
Imagine you're building a fraud detection system. Using linear regression, the model might predict the likelihood of a transaction being fraudulent based on fixed parameters like transaction amount or time. The results are consistent and explainable. The same inputs will always yield the same fraud score. However, linear regression may struggle to capture complex patterns, such as relationships between user behavior and transaction history.
Switching to a neural network allows the model to learn these intricate patterns and improve accuracy. However, training the same neural network multiple times might yield slightly different fraud scores for the same transaction because of its non-deterministic nature. While this can lead to more nuanced detection, it also introduces challenges in debugging, reproducibility, and explaining the results to stakeholders.
Choosing between deterministic and non-deterministic models depends on the trade-off between interpretability and the complexity of the patterns your model needs to capture.
Since the world is not black and white, a hybrid solution can help in cases where you would require deterministic systems (e.g., Coupling a graph database or linear regression model with a neural network implementation.) In case both identify a transaction as “fraudulent,” it can be marked “fraudulent” by the system. In case both identify it as “correct,” it can be marked “correct” by the system. In the other two cases, it will require human intervention to investigate on the transaction. The result will be one of the two models needs tweaking.
In this context, it is important that your platform is flexible and scalable (e.g., Red Hat OpenShift) to allow for flexible platform designs.
Overfitting
Overfitting in machine learning occurs when a model learns the training data too well, including its noise and minor details, to the point that it performs poorly on new, unseen data. The model becomes overly specialized, losing its ability to generalize. In this instance, understanding the data is important and having monitoring and observation capabilities in place is really important. So make sure your AI-platform (i.e., OpenShift and Red Hat OpenShift AI) provides these capabilities for you without too much effort.
For example, iImagine training a model to recognize chocolate cookies based on images. If the model learns to identify cookies only when the chocolate chips are in the exact same position as in the training examples, it will fail to recognize a cookie with a slightly different chocolate chip pattern. This is overfitting, focusing too much on specific details of the training data rather than understanding the broader concept of a chocolate cookie (Figure 7).

In this context, it is crucial to understand your data and to have robust monitoring and observation capabilities. These enable you to track model performance and identify potential issues like overfitting or drift. Ensure your AI platform (i.e., OpenShift and OpenShift AI) offers these capabilities seamlessly, so you can focus on innovation without getting overwhelmed by operational complexity.
Closing thoughts: The strategic value of AI/ML
AI/ML is not just a technology decision but a strategic one. These models can unlock insights and efficiencies that were previously unimaginable, driving business transformation at every level. By investing in AI/ML, your organization can stay ahead of the competition, enhance decision-making processes, and create new value for customers.
It’s not necessary to dive into the technical details of how every algorithm works, but understanding the potential AI/ML holds for your business and having the right team to implement it can set you up for long-term success.
If you'd like to dive deeper into how specific AI/ML models can be applied to your industry, let’s connect. Be sure to check out our next articles.
Last updated: April 16, 2025