The goal of this series of posts is to describe a proposed approach for an agile API delivery process. It will cover not only the development part but also the design, the tests, the delivery, and the management in production. You will learn how to use mocking to speed up development and break dependencies, use the contract-first approach for defining tests that will harden your implementation, protect the exposed API through a management gateway and, finally, secure deliveries using a CI/CD pipeline.
I coauthored this series with Nicolas Massé, who is also a Red Hatter. This series is based on our own real-life experience from our work with the Red Hat customers we’ve met, as well as from my previous position as SOA architect at a large insurance company. This series is a translation of a typical use case we run during workshops or events such as APIdays.
Background
As IT becomes a core competency for enterprises in order to keep a fast pace of innovation, most companies are now turning into software companies. And they are in the process of rethinking the way they are building and running IT to prepare for the explosion of new digital services to come. This trend leads to modern software architecture paradigms such as APIs and microservices.
Because API management solutions are becoming mainstream, it has gotten easier to securely expose APIs to the world. However, doing this isn't a complete solution. The whole API lifecycle should go agile too in order to stay relevant. Paradoxically, this difficult to do because new a service-based architecture makes dependencies skyrocket.
Thus, it’s time to think of a new way to deliver APIs—mocking and testing included—to simplify and accelerate the shipping of production-ready APIs backed by microservices.
Concrete Use Case
Before we dig in, let’s examine a use case that will help illustrate this approach through an example: the use case of ACME Inc., a local brewery. ACME produces, stores, and distributes beers to its beloved customers, and the whole process is managed in-house.

The increasing competition and the growing demand of the customer base are forcing ACME to rethink its distribution model. Namely, the distribution will be left to independent resellers that could sell beers locally, online or on-site. The main challenge is how to open up the information system so that independent resellers can discover the beer catalog, check inventory, and so on. This can be done through the exposition of an API, of course.

Technologies and Material
The technologies we’ll use to help guide ACME Inc. on this journey are:
- API design tool (Apicurio Studio)
- Mocking and testing tool (Microcks)
- API testing and editing tool (Postman)
- Service development framework (Spring Boot)
- Deployment/CI-CD platform (Kubernetes/OpenShift)
- API management tool (3scale)
You might want just read this series, but if you want to go further by replaying the whole use-case demonstration, all the material for that (source code, scripts, setup procedures) can be found in this GitHub repository: https://github.com/microcks/api-lifecycle/tree/master/beer-catalog-demo.
Milestone 0: API Ideation
Although most API lifecycle definitions start with the design phase and best practices te a contract-first approach, we all know that it is really hard to start from scratch with API contract design. It’s usually helpful to have a sandbox to test what future APIs should look like. A sandbox allows us to play and illustrate API methods and resources. It should us allow to rapidly test and share different designs for an API.
We can see different approaches regarding tooling for this phase.
The “local” approach consists of using a local tool that is dedicated to simulation. Some tools such as Hoverfly shine at this, because they are able to use local JSON file definitions to simulate an API. However, these tools are mostly targeting developers and their “local” nature make it hard to easily share and tests multiple designs in the mid- or long-term.
We prefer a “team” approach that we think makes more sense in an enterprise context. A ready-to-use platform can allow us to host and share different tests. This is one of the purposes of Microcks, a communication and runtime tool for mocking and testing. Microcks can be easily set up on Kubernetes or OpenShift and provides a “back end as a service” feature called dynamic service.
Just give it the name and the version of your API, and it generates a basic CRUD REST API for you. For our ACME use case, we will create the Beer Catalog API on version 0.1 to allow us to play with beer resources.
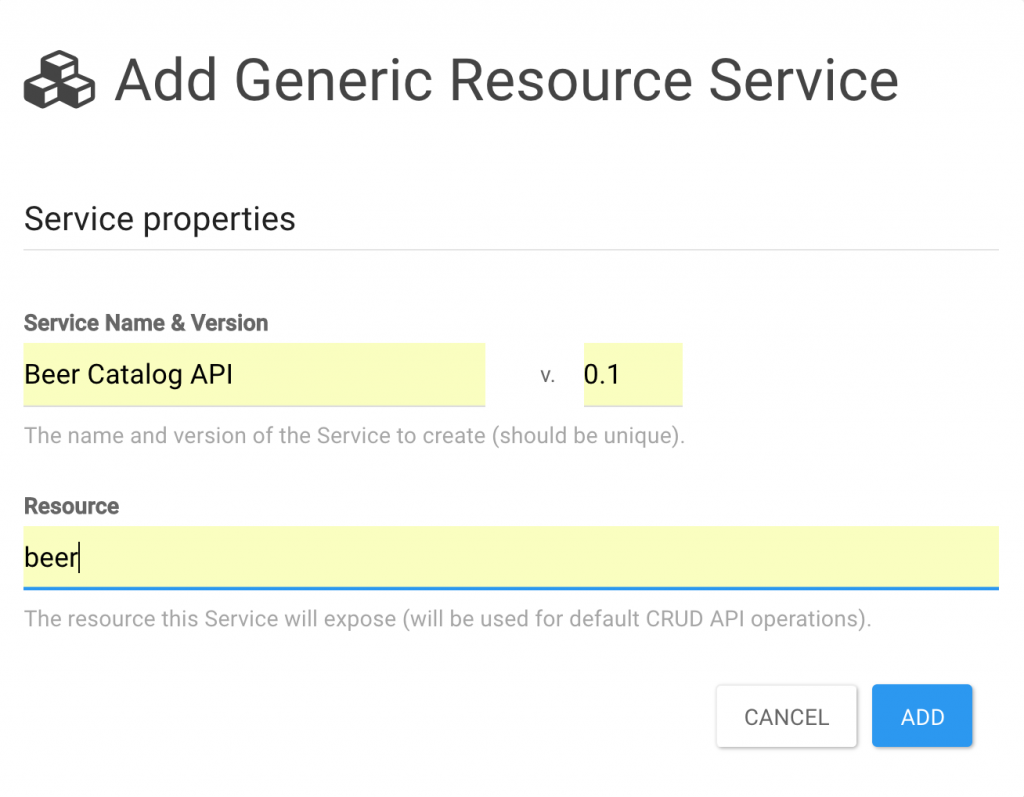
Dynamic endpoints for your new API are instantly made available for you. The details page for your dynamic service gives you information about the operations made available as well as the endpoint URL.
You’re now able to start using this sample API and recording new beer resources within the sandbox by appending the Mock URL to the Microcks base URL :
$ curl -X POST 'http://microcks.example.com/dynarest/Beer%20Catalog%20API/0.1/beer' -H 'Content-type: application/json' -d '{"name": "Rodenbach", "country": "Belgium", "type": "Brown ale", "rating": 4.2}'
$ curl -X POST 'http://microcks.example.com/dynarest/Beer%20Catalog%20API/0.1/beer' -H 'Content-type: application/json' -d '{"name": "Westmalle Triple", "country": "Belgium", "type": "Trappist", "rating": 3.8}'
$ curl -X POST 'http://microcks.example.com/dynarest/Beer%20Catalog%20API/0.1/beer' -H 'Content-type: application/json' -d '{"name": "Weissbier", "country": "Germany", "type": "Wheat", "rating": 4.1}'
You can check the created resources from the details page. Now everyone who has access to Microcks is also able to review your sample API and the recorded resources.
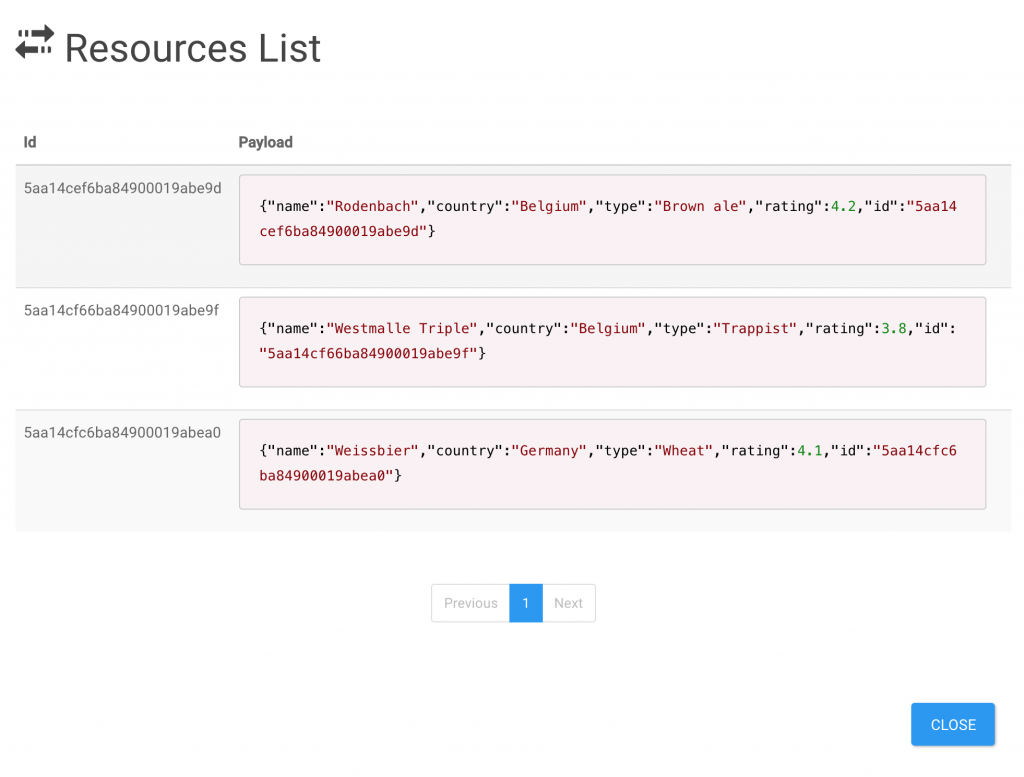
You’re also able to query resources using different methods.
$ curl 'http://microcks.example.com/dynarest/Beer%20Catalog%20API/0.1/beer/'
[{ "name" : "Rodenbach", "country" : "Belgium", "type" : "Brown ale", "rating" : 4.2, "id" : "5aa14cef6ba84900019abe9d" }, { "name" : "Westmalle Triple", "country" : "Belgium", "type" : "Trappist", "rating" : 3.8, "id" : "5aa14cf66ba84900019abe9f" }, { "name" : "Weissbier", "country" : "Germany", "type" : "Wheat", "rating" : 4.1, "id" : "5aa14cfc6ba84900019abea0" }]
$ curl 'http://microcks.example.com/dynarest/Beer%20Catalog%20API/0.1/beer/5aa14cfc6ba84900019abea0'
{ "name" : "Weissbier", "country" : "Germany", "type" : "Wheat", "rating" : 4.1, "id" : "5aa14cfc6ba84900019abea0" }
$ curl 'http://microcks.example.com/dynarest/Beer%20Catalog%20API/0.1/beer' -H 'Content-type: application/json' -d '{"country": "Belgium"}'
[{ "name" : "Rodenbach", "country" : "Belgium", "type" : "Brown ale", "rating" : 4.2, "id" : "5aa14cef6ba84900019abe9d" }, { "name" : "Westmalle Triple", "country" : "Belgium", "type" : "Trappist", "rating" : 3.8, "id" : "5aa14cf66ba84900019abe9f" }]
Microcks provides you with a complete sandbox for iterating, testing different resources representations, sharing them and—most importantly—allowing their integration with some consumer apps for real-life tests. The sandbox gives also helpful samples of resources for the following design phase.
Milestone 1: API Contract Design
The purpose of this phase is to create an API contract artifact covering the technical and syntactic definition of the future API. A contract provides a clear description of the API methods and custom resources manipulated. It represents the cornerstone of a service-based architecture, and we’ll see later in this series how it can be help speed up things and assess future implementations.
Different attempts at standardization the last few years have finally made OpenAPI Specification (formerly the Swagger Specification) emerge as the standard to use. It tes YAML and JSON as the de facto languages for specifying a contract.
Here again, you can choose different paths regarding tooling. We still prefer the “team” approach that enables collaborative practices when designing an API contract. Moreover, we’ve found that a team approach helps with building a repository of the dozens of API contracts an enterprise may govern.
Apicurio Studio provides an online collaborative editor for API contracts. It’s a WYSIWYG editor that simplifies API design by providing immediate feedback on compliance with the OpenAPI Specification.
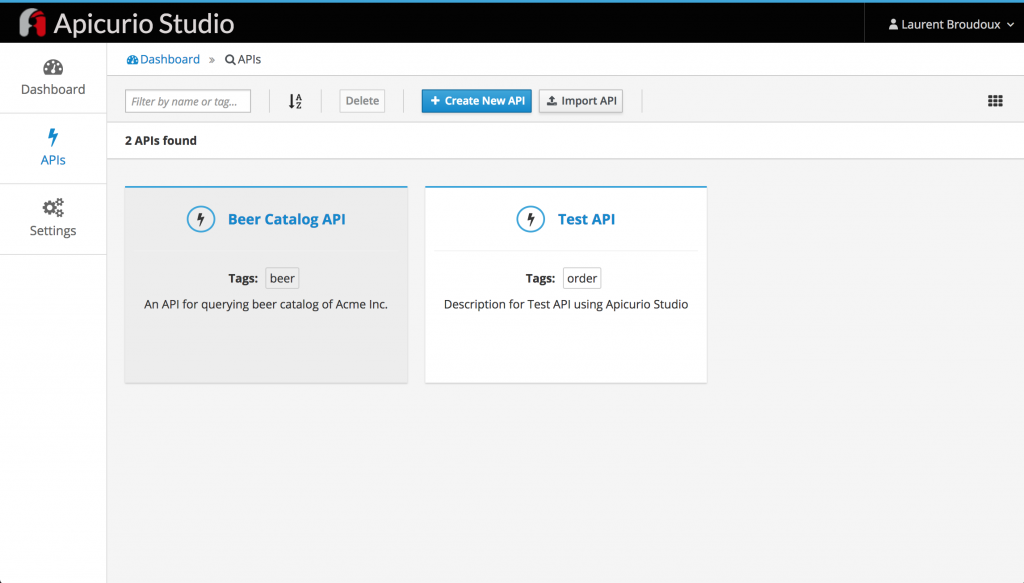
Apicurio Studio provides a dashboard and facilities for browsing your APIs through tags, importing, or creating brand new API definitions. For our ACME use case, we will create a new Beer Catalog API with a version 0.9. Thanks to our previous sandbox tests, ACME was able to precisely define its needs and requires only API methods for browsing the beer catalog.
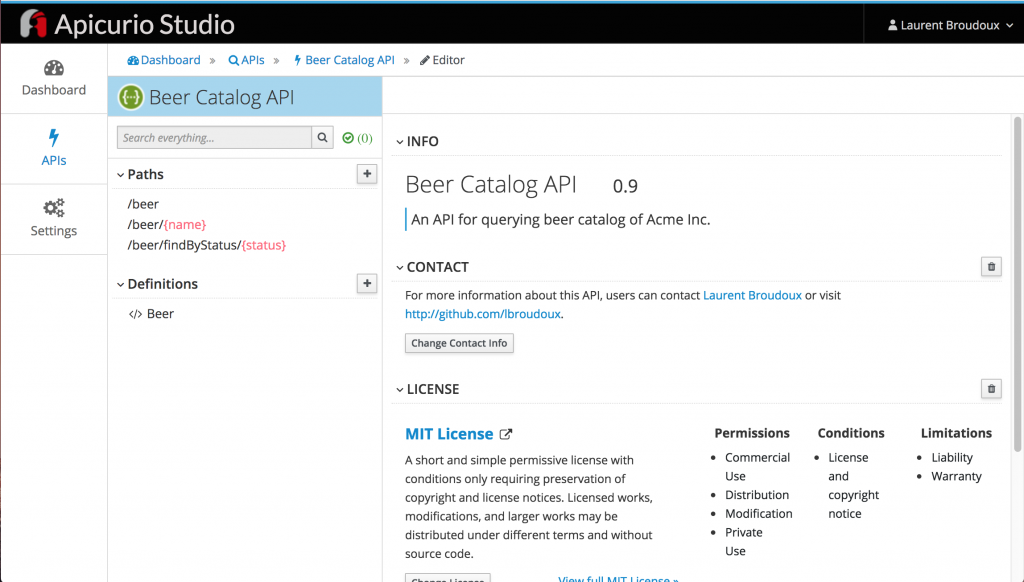
ACME has also been able to detail the definition of the beer resource: identifying the mandatory and the optional attributes of the data model.
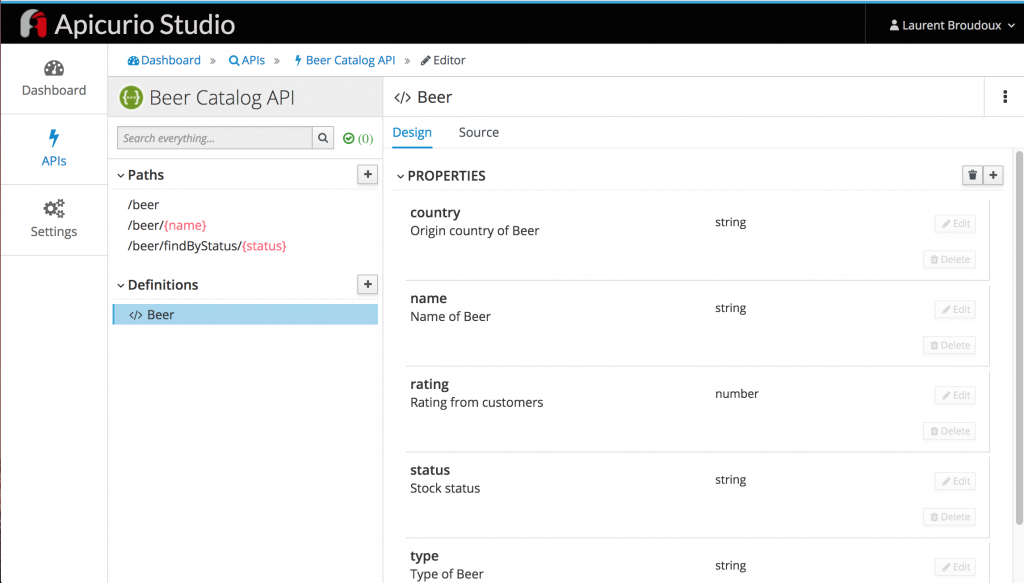
All these edit operations are made easily with validation on the fly. Then everything can be saved and versioned into a Git repository. If you want to have a look at the final result, check our copy: https://github.com/microcks/api-lifecycle/blob/master/beer-catalog-demo/api-contracts/beer-catalog-api-swagger.json
Milestone 2 Expectations and Request/Response Samples
This stage is usually neglected or ignored when building service-based architecture applications. One mistake people usually make is starting right away with the implementation without taking the small amount of time needed for this step. However—and this was introduced in another blog post—service contractualization sampling is a strategic step because it allows you to parallelize the development of both the provider and consumers of services and it enables efficient contract testing of your API.
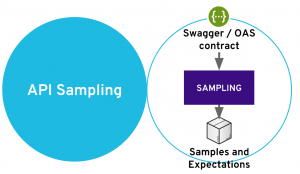
While it’s technically feasible to mock from a contract, we think it’s better to use representative samples to get the most of the business logic. Request/response samples expertly illustrate common and edge cases of the future API.
This stage should also be dedicated to the explicitly defining business expectations that cannot be described using only a technical contract. We can easily use sampling to set up explicit assertions about what response is expected for an incoming request.
The typical illustration of such a rule is that of the filtered query. Imagine you are offering an API that enables searching items using filters; all the response items should have their values specified as criteria. This may sound obvious but in reality, implementations may easily fail to fulfill this expectation. Another typical use case in financial services is the requirement of a minimum age for subscribing to or purchasing a product. Using sampling and expectations, it is really easy to describe that use case and the message that should appear if the minimum age is not met.
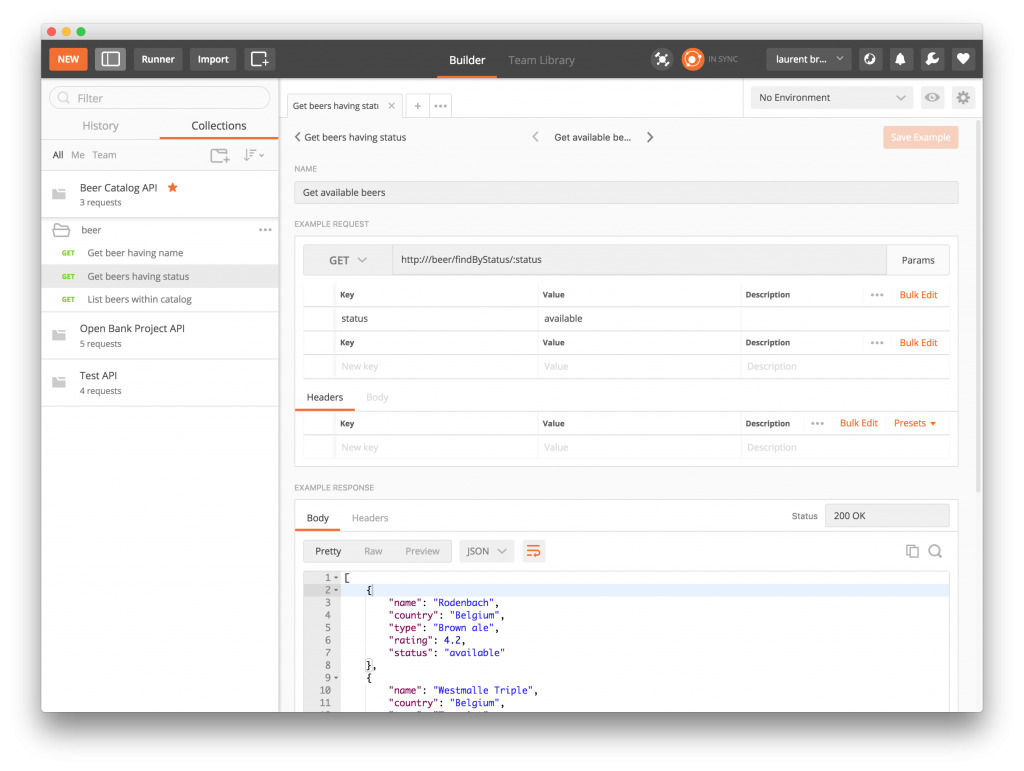
A simple and efficient tool for doing that is Postman. This is because we’re dealing with a modern REST API, but the same principle would apply with legacy SOAP web services by using SoapUI tooling. Using Postman, we’ll be able to describe real-world requests and responses and then save anything as a JSON file called a collection.
For our ACME use case, for example, we first import the OpenAPI Specification we previously created with Apicurio. Then, it is really easy to add some examples for specifying what a response to a “Get beers having the available status” request should look like.
We can also specify expectations with Postman using its tests. Tests are not defined specifically for a sample but globally at the method level. Thus, it condenses all the common, edge, and exception cases of a method. Tests are specified using JavaScript snippets.
In our ACME example, we want to check the filtered query case we described above. This can be done easily by defining a new inline schema definition that restricts the value of the status attribute to the value that is expected.
var expectedStatus = globals["status"];
var jsonData = JSON.parse(responseBody);
var schema = {
"type": "array",
"items": {
"type": "object",
"properties": {
"name": { "type": "string" },
"country": { "type": "string" },
"type": { "type": "string" },
"rating": { "type": "number" },
"status": { "type": "string", "enum": [expectedStatus] }
}
}
};
tests["Valid status in response"] = tv4.validate(jsonData, schema);
All this information is saved within the collection, which can be later exported and versioned in Git. It’s definitely a good practice to version everything. It also helps other people to contribute sample data and expectations in a consumer-driven contract way.
Key Takeaways
So far, we have seen how ACME has started its API journey through the first three stages:
- Ideation to mature their needs using a sandbox.
- Contract design to specify the methods, documentation, and data structures of the API.
- Sampling as an extra step allowing the communication of real-life samples and expectations. We'll see that it is also an enabler for parallelized development and automated testing.
Stay tuned for part II in which you will learn how to deploy a mock from the defined examples and much more.
