In today's container-driven landscape, Kubernetes has emerged as the leading platform for orchestrating distributed applications at scale through containers.
However, effectively managing a Kubernetes cluster demands comprehensive visibility into its current resources. This is where data collection and reporting come into play, acting as crucial tools for monitoring system integrity, identifying potential issues, and optimizing resource utilization.
In this blog post, we will explore how Ansible, a powerful open-source automation tool, can streamline data collection from Kubernetes clusters and generate detailed reports for enhanced management and control. We will discover how Ansible can extract key information such as CPU and memory configurations as well as other interesting information about cluster’s nodes, providing a holistic overview of the Kubernetes environment. Additionally, we will demonstrate how Ansible can transform this data into customized reports in various formats, offering a clear and accessible view of cluster configuration.
Get ready to delve into the world of data collection and reporting with Ansible for Kubernetes, and learn how to transform your data into valuable insights for optimizing your operations and making informed decisions.
Ansible collections and modules to use
Let’s first analyze the modules and collections that we will leverage to get into our Kubernetes cluster. Before going into the details, it’s worth mentioning a bit of history regarding Ansible Collections.
Ansible Collections were introduced as a new way to distribute and organize Ansible content in versions after 2.4. They replaced the older method of including modules directly in the core Ansible repository. This helped in many ways the Ansible development and maintenance improving the Packaging, the Modularity and the Distribution.
Overall, Ansible Collections provide a more organized, modular, and discoverable way to manage Ansible content.
For our data-gathering playbook we will leverage three modules
- kubernetes.core.k8s_info
- ansible.builtin.copy
- ansible.builtin.template
And one filter to export the raw data for debugging purposes
- ansible.builtin.to_nice_json
The kubernetes.core.k8s_info module
This module in Ansible is used to gather information about objects within a Kubernetes cluster. It's part of the kubernetes.core collection, which needs to be installed separately from the core Ansible package, but luckily this is already included in the Ansible Automation Platform Execution Environment we are going to use.
You can find more info about this Ansible module in the documentation at docs.ansible.com/ansible/latest/collections/kubernetes/core/k8s_info_module.html
The Ansible Playbook and the Ansible Template
Just to recap the main concepts behind Ansible Playbooks, they are written in YAML and define a set of instructions (tasks) to be executed on managed hosts (controlled by the inventory). Playbooks are human-readable and easy to understand.
Next, you can find the main Ansible Playbook we will use to gather data from OpenShift nodes.
---
- name: Extract data from OpenShift
hosts: localhost
tasks:
- name: Gather data from the nodes
kubernetes.core.k8s_info:
kind: Node
register: node_list
- name: Export the data to json file
ansible.builtin.copy: content="{{ node_list | to_nice_json }}" dest="./nodes_output.json"
- name: Output the report with the template
ansible.builtin.template:
src: templates/node-report.csv.j2
dest: "./nodes_report.csv"Let’s analyze it by analyzing one task at the time. As you can see above, the first task is to contact the remote Kubernetes cluster requesting all the resources of the Node kind, saving the data in the node_list variable.
We are not defining any authorization configuration, the module connect to our Kubernetes cluster leveraging the kubeconfig configuration file, generated after a successful authentication with a Kubernetes cluster, placing it in the default path. The kubernetes.core.k8s_info will look for a kubeconfig file in the default path and it will use it for establishing an authenticated connection.
The second task, save the data gathered from the Kubernetes cluster, saving it into a JSON file. In this task, we are appending the to_nice_filter to output a human-readable JSON as a source for our copy module action.
Finally the last task creates the report that we are waiting for, a CSV file, well-formatted, extracting the data we may need for our reporting activities. We will look at the template structure in the next paragraph.
Next, you can find the main companion for our Ansible Playbook, the Ansible Template producing a well-formatted CSV file.
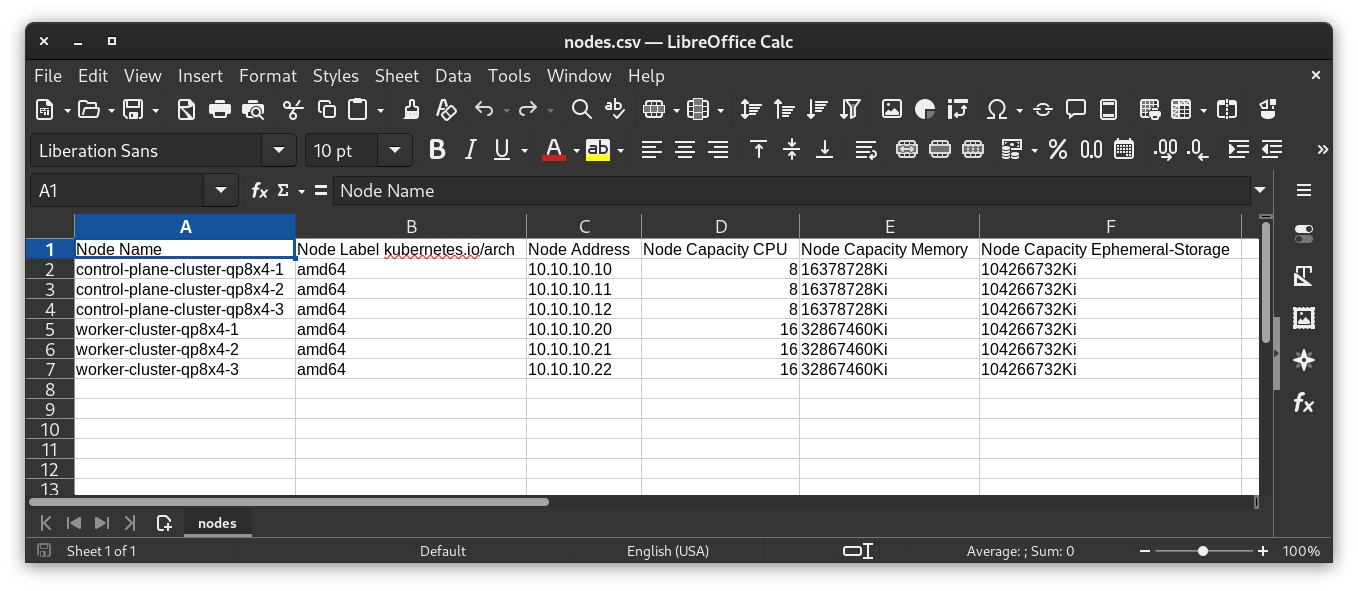
Node Name,Node Label kubernetes.io/arch,Node Address,Node Capacity CPU,Node Capacity Memory,Node Capacity Ephemeral-Storage
{% for node in node_list.resources %}
{{ node.metadata.name }},{{ node.metadata.labels['kubernetes.io/arch'] }},{{ node.status.addresses[0].address }},{{ node.status.capacity.cpu }},{{ node.status.capacity.memory }},{{ node.status.capacity['ephemeral-storage'] }}
{% endfor %}As you can imagine this is just an example and you can change the column and the value extracted as you need to produce the most comprehensive report. You can customize the extraction as you want, using the JSON file created with the Ansible Playbook.
After defining the first row of our CSV file, we are then going to print in the final template the data rows, extracting the data from the data variable that the kubernetes.core.k8s_info created for us. To iterate the data extraction we are using the for loop available in the Jinja2 syntax.
Test the Ansible Playbook and get the CSV report
The ansible-playbook command interprets the YAML playbook file, executes the tasks defined within, and manages the communication with the target systems.
To use the ansible-playbook command you have to ensure to have a recent Ansible version installed on your control machine. Then the tasks defined in the playbook might reference specific Ansible modules. These modules might be part of the core Ansible installation, while others might require additional collections to be installed.
Now we are not going through how to install and configure Ansible and its dependencies or modules but I will share a trick with you to simplify Ansible's development and testing activities.
The steps below require a Red Hat Ansible Automation Platform subscription, in case you don’t, you can still request a Red Hat Developer Subscription for personal usage activities at developers.redhat.com/register.
We will leverage the default Execution Environment for Ansible Automation Platform (AAP) 2.4, this will help and simplify the execution of our Ansible Playbook. Alternatively you can give a try with AWX Execution Environments at quay.io/repository/ansible/awx-ee.
Ansible Execution Environments (EEs) are a relatively new feature introduced in Ansible Automation Platform version 2. They provide a containerized approach to running Ansible playbooks, offering several advantages over traditional methods like: Improved Portability, Enhanced Security and Simplified Dependency Management.
Download the AAP 2.4 Execution Environment
First of all we have to authenticate to registry.redhat.io, the Red Hat’s enterprise container registry, through Podman.
Podman is an open-source container engine for Linux that stands out for its lightweight and efficient approach. Unlike Docker, it doesn't require a constantly running daemon, making it a resource-friendly option.
If you are not so familiar with Podman you may find a lot of documentation, examples and blog posts on the internet. You can even take a look to an old blog post I wrote back in 2018 developers.redhat.com/blog/2018/08/29/intro-to-podman.
Let’s start the login process, it will ask for our Red Hat credentials, as you can see in the next example.
alezzandro@penguin:~$ podman login registry.redhat.io
Username: alezzandro
Password:
Login Succeeded!Then we can pull the AAP Execution Environment container image, as shown next.
alezzandro@penguin:~$ podman pull registry.redhat.io/ansible-automation-platform-24/ee-supported-rhel8:latestPrepare the kubeconfig authentication file
Before running the AAP Execution Environment we have to get a working kubeconfig file. This file is needed by the Ansible Kubernetes module to connect to our cluster to gather the data.
If you are not familiar with this kind of configuration I will show an easy method to get, supposing you are working with Red Hat OpenShift Container Platform (OCP) or OpenShift Kubernetes Distribution (OKD).
Login to your OpenShift’s cluster web interface and click on your username in the upper right bar, as shown in the next image.
Then click on "Copy login command" button to get the example command to launch on your Linux terminal (for this you will need the openshift-client package installed on your Linux system). You can find an example in the next section.
alezzandro@penguin:~$ oc login --token=sha256~YOUR-SUPER-SECRET-TOKEN --server=https://api.cluster-qp8x4.dynamic.yourcluster.local:6443As you can verify on your system, the previous command should create a default kubeconfig file you can inspect, as shown next.
alezzandro@penguin:~$ ls -la .kube/config
-rw------- 1 alezzandro alezzandro 695 Apr 20 16:53 .kube/configRun the Ansible Playbook via the Execution Environment
Before launching the container, we need to move in our Ansible project working dir, the directory containing the Playbook and the Template we created. I have set up a quick git project for letting you test and work on your reports, it is available here github.com/alezzandro/ansible-openshift-reports.
After that we are ready to start the AAP Execution Environment thanks to Podman container engine.
alezzandro@penguin:~/gitprojects/ansible-openshift-reports$ podman run -ti -v /home/alezzandro/gitprojects/ansible-openshift-reports:/runner/project:Z -v /home/alezzandro/.kube/config:/home/runner/.kube/config:Z registry.redhat.io/ansible-automation-platform-24/ee-supported-rhel8:latest /bin/bash
bash-4.4# The previous command will get us a shell inside the container, then we can run the playbook.
bash-4.4# cd project
bash-4.4# ansible-playbook openshift-nodes.yamlThe ansible-playbook command will produce something similar to the output shown in the next image.
As shown before, the Ansible Playbook will produce the CSV report that we can then even open with our favorite Spreadsheet editor, you will find an example in the next picture.
In conclusion, Ansible empowers you to streamline data collection from Kubernetes clusters and transform that data into actionable insights.
By leveraging the kubernetes.core.k8s_info module, you can gather critical metrics about your deployments, while the ansible.builtin.template module enables you to generate human-readable reports tailored to your needs.
This data-driven approach empowers you to monitor cluster health, identify potential issues, and optimize resource utilization.
With Ansible, you gain valuable visibility and control over your Kubernetes deployments, ensuring their smooth operation and informed decision-making.
Have fun with Ansible!
