Integrated hybrid cloud MLOps and Application Platform
A common platform for machine learning and app development on the hybrid cloud.

A common platform for machine learning and app development on the hybrid cloud.
Red Hat’s integrated hybrid cloud AI/ML platform provides a consistent way to support the end-to-end lifecycle of both machine learning (ML) models and cloud native applications in terms of how they are developed, packaged, deployed, and managed.
This AI/ML platform consists of Red Hat OpenShift AI built on top of Red Hat OpenShift and their ecosystem of open source and ISV software.
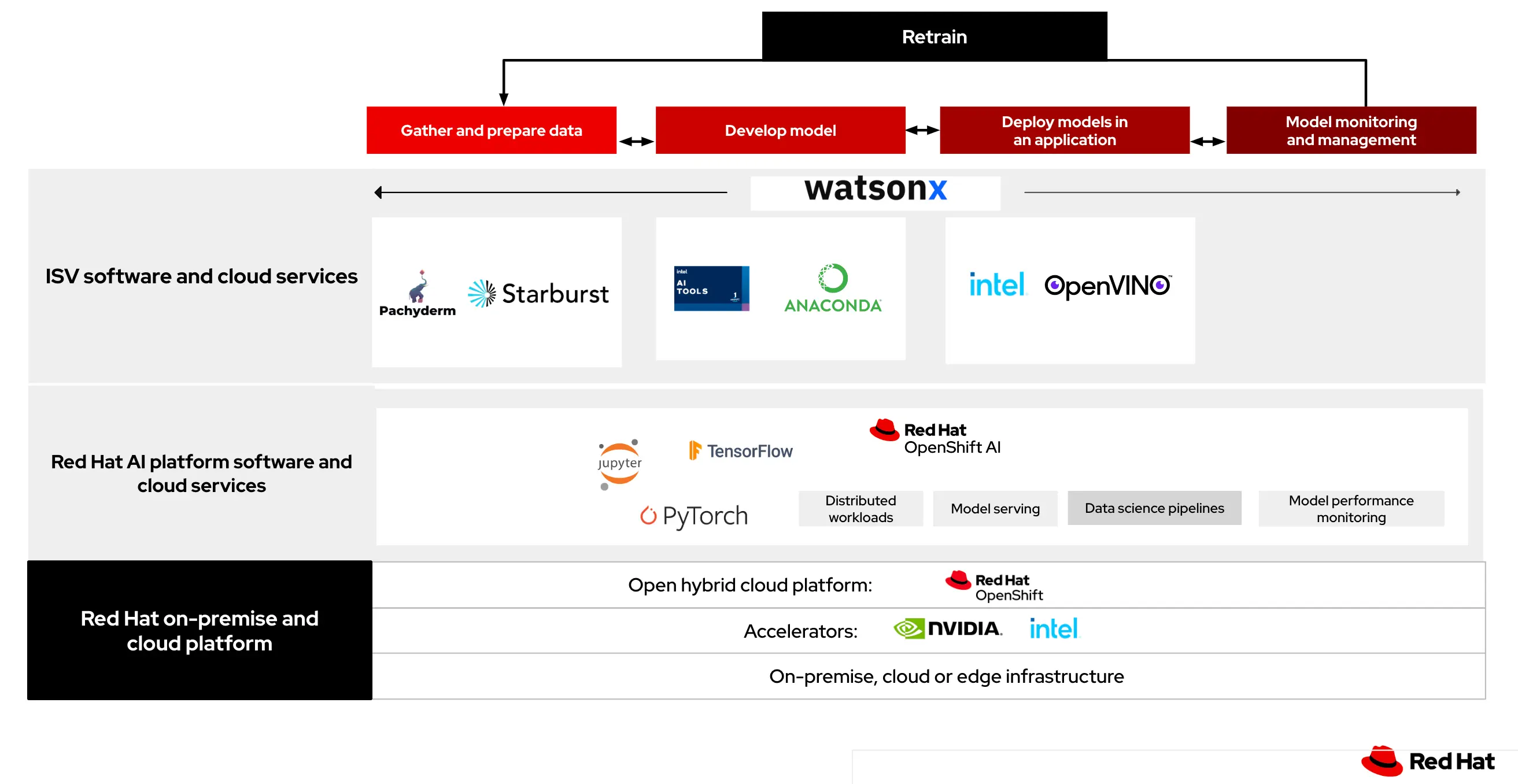
Red Hat OpenShift AI (RHOAI), based on Open Data Hub , is an open source, community-driven AI platform. It is designed for the hybrid cloud and built on popular open source AI tools.

Red Hat OpenShift is a Kubernetes-powered application platform with open source-based application lifecycle capabilities. These capabilities include:
These frameworks and languages code business logic and Integration services like API Gateway, Single Sign-On (SSO), and 3scale API Management to expose and connect the applications securely and at scale.
The following figure shows the steps involved in operationalizing AI/ML models and cloud native applications that utilize those models to deliver intelligent experiences to customers.
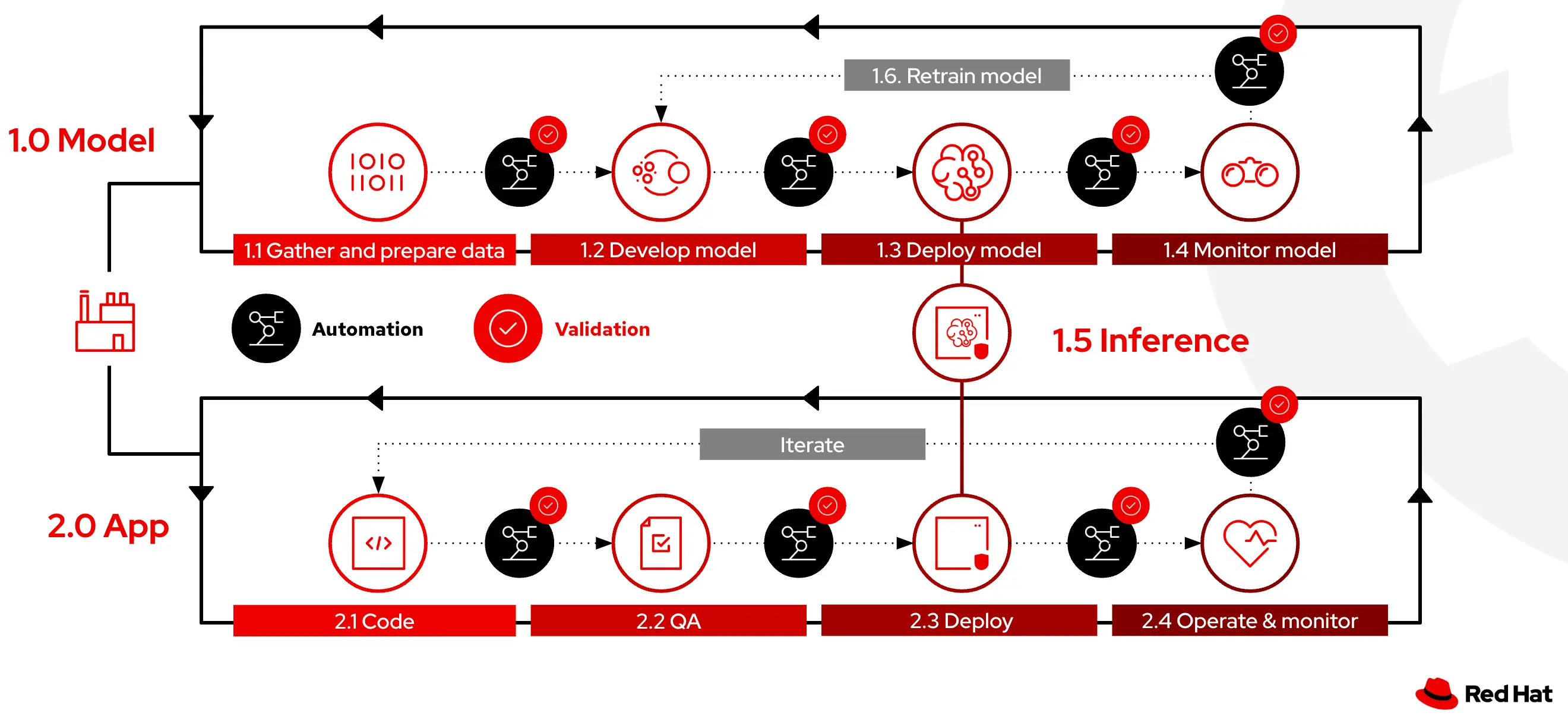
Red Hat OpenShift AI is a flexible, scalable MLOps platform built on open source technologies with tools to build, deploy, and manage AI-enabled applications. This MLOps platform provides trusted and operationally consistent capabilities for teams to experiment, serve models, and deliver innovative apps. How this platform enables the MLOps Lifecycle is explained below.

In this step, data scientists import data into a specialized environment known as a workbench. This environment is designed for data science tasks and is hosted on OpenShift, offering a containerized, cloud-based workspace. Equipped with tools such as JupyterLab and libraries like TensorFlow, it also includes GPU support for data-intensive and generative AI computations. Data can be uploaded directly to the workbench, retrieved from S3 storage, sourced from databases, or streamed.
RHOAI provides:

In this step, the model is trained using data that has already been cleaned and prepared. To assess how well the model performs, it is tested against specific subsets of the data designated for validation and testing. These subsets are selected from the overall dataset to check the model's effectiveness in dealing with data it has not previously encountered, ensuring it can accurately make predictions on new samples. Iteration is necessary to achieve the desired result. Data scientists typically go through several iterations of this process, refining the model by repeating the steps of data preparation, model training, and evaluation. Data scientists continue this iterative process until the model's performance metrics meet their expectations.
To support these activities, RHOAI offers:

After the model is trained and evaluated, the model files are uploaded to a model storage location (AWS S3 bucket) using the configuration values of the data connection to the storage location. This step involves the conversion of the model into a suitable format for serving, such as ONNX. Deploying the model for serving inferences involves creating model servers that fetch the exported model from a storage location (AWS S3) using data connections, and exposing the model through a REST or a gRPC interface. To automatically run the previous series of steps, when new data is available, engineers implement data science pipelines which are workflows that execute scripts or Jupyter notebooks in an automated fashion.
RHOAI provides:

In dynamic production environments, deployed models face the challenge of model drift due to evolving data patterns. This drift can diminish the model's predictive power, making continuous monitoring essential. With RHOAI, machine learning engineers and data scientists can monitor the performance of a model in production by using the metrics gathered with Prometheus.

After a model is deployed in the production environment, real world data is provided as input and through a process known as Inference, where the model calculates or generates the output. In this stage, it is of prime importance to ensure minimal latency for optimal user experience.
RHOAI delivers:

Model retraining is done based on performance metrics that are monitored in production. Since it is quite common to have dynamically changing data, it is important to standardize and automate model retraining via retraining pipelines using the Pipelines capabilities of RHOAI mentioned previously.
OpenShift is a complete hybrid cloud platform that brings together developers, platform engineers, and operations teams on one platform to efficiently develop, deploy, and manage a wide variety of workloads. How this platform enables the Cloud Native Intelligent Application Lifecycle is explained below.

In this step, developers focus on writing business logic using a consistent, modern, and supported programming language runtime. They also need to use platform services like authentication, logging, scaling, and resource management.
OpenShift provides:

Customer and business needs require developers to provide a continuous delivery of new features and a quick turnaround time to production for bug fixes. Testing cloud native apps is complex due to their distributed nature and the number of dependencies involved.
OpenShift provides:
Cloud native applications need an efficient, scalable, and consistent deployment mechanism with version control to make these applications available to users and ongoing resource management to be able to scale these applications up and down based on the demand. Applications need capabilities like automated builds, creation of container images hosting these images in an image registry, and deployment of images across hybrid cloud environments.
OpenShift provides these capabilities natively through:

In production, cloud native applications need observability capabilities that help identify, troubleshoot, and fix issues in real-time to ensure scalability, security, governance, and compliance with regulatory requirements.
OpenShift provides:
Try these self-directed learning exercises to gain experience and bring your creativity to AI and Red Hat OpenShift AI – Red Hat’s dedicated platform for building AI-enabled applications. Learn about the full suite of MLOps to train, tune, and serve models for purpose-built applications.

Learn the foundations of Red Hat OpenShift AI, that gives data scientists and developers a powerful AI/ML platform for building AI-enabled applications. Data scientists and developers can collaborate to move quickly from experiment to production in a consistent environment.

Create a demo application using the full development suite: MobileNet V2 with Tensor input/output, transfer learning, live data collection, data preprocessing pipeline, and modeling training and deployment on a Red Hat OpenShift AI developer sandbox.

Learn engineering techniques for extracting live data from images and logs of the fictional bike-sharing app, Pedal. You will deploy a Jupyter Notebook environment on Red Hat OpenShift AI, develop a pipeline to process live image and log data, and also extract meaningful insights from the collected data.

Discover a new combinatorial approach to decoding AI’s hidden logic,...

Discover how to fine-tune large language models (LLMs) with Kubeflow...

The technology preview of incident detection is now available in the Red Hat...

Explore how Red Hat Developer Hub and OpenShift AI work together with...

Build here. Go anywhere.
We serve the builders. The problem solvers who create careers with code.
Join us if you’re a developer, software engineer, web designer, front-end designer, UX designer, computer scientist, architect, tester, product manager, project manager or team lead.