Machine learning helps us make better decisions by learning from existing data models and applying good predictions to the next output. This article explores ways to apply machine learning in each phase of the GitOps life cycle. With machine learning and GitOps, we can:
- Improve deployment accuracy and predict which deployments will likely fail and need more attention.
- Streamline the deployment validation process.
- Enhance existing quality metrics and drive better deployment results.
Automating your infrastructure with GitOps
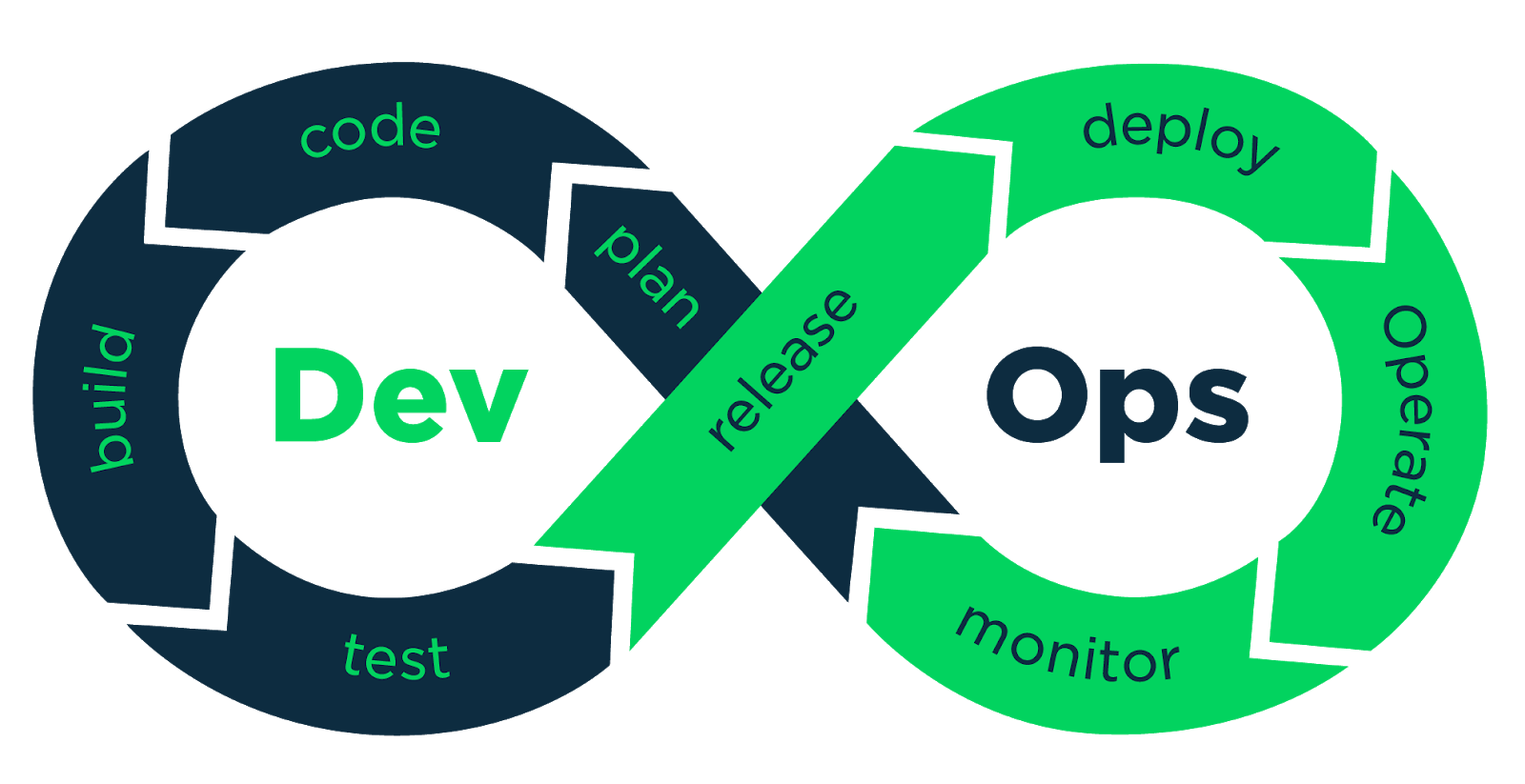
Git supports collaboration between developers by tracking changes in commit history. It applies changes to the desired states as version-controlled commits. DevOps speeds up the process from development to deployment in production. DevOps practitioners use CI/CD to automate builds and deliver iteratively, relying on tools like Jenkins and Argo CD to apply version control to application and infrastructure code. Figure 1 shows the phases of the DevOps development cycle.
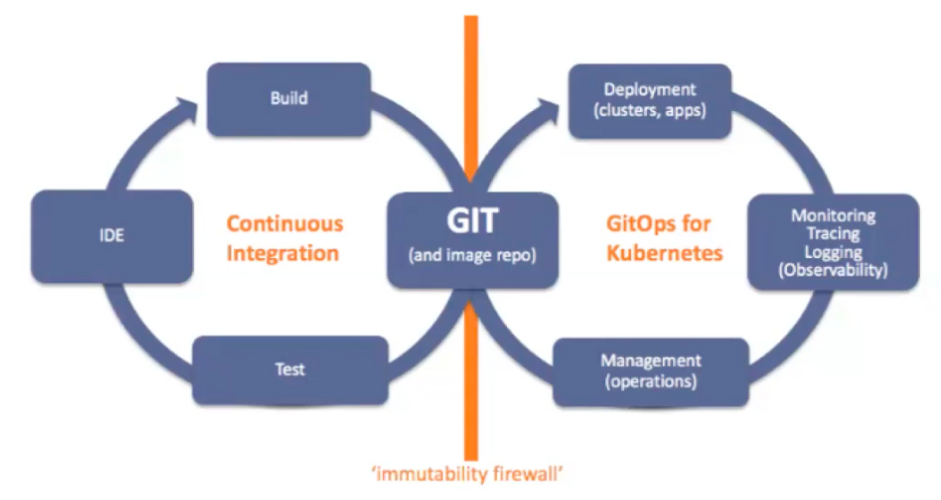
When we combine Git and DevOps, we get GitOps. GitOps is DevOps for infrastructure automation. It is a developer workflow for automating operations. Figure 2 shows the phases of the GitOps development life cycle.
GitOps and machine learning
With GitOps, we track code commits and configuration changes. Changes made to the source code go into an image repository like Docker Hub. This practice is called continuous integration and can be automated with Jenkins. On the other hand, configuration changes are driven by Git commit. We put the files in Git and synchronize them in Kubernetes. We can use tools like Argo CD to continuously monitor applications running in the cluster and compare them against the target state in the Git repository. This lets Kubernetes automatically update or roll back if there is a difference between Git and what’s in the cluster. With GitOps, developers can deploy many times a day, allowing for higher velocity.
In the next sections, we'll discuss how machine learning (ML) accelerates each step in the GitOps cycle—that is, how it reduces maintenance in building, testing, deploying, monitoring, and security scanning. We'll also look at using machine learning to automatically generate tests for validation.
Speed up the build process with predictive builds
First, machine learning speeds up the build process. Traditionally, GitOps uses information extracted from build metadata to determine which packages to build when there is a particular code change. By analyzing build dependencies in code, GitOps determines all packages that depend on the modified code and rebuilds all of the dependency packages.
With machine learning, we can avoid rebuilding all of the dependency packages. Instead, we train the system to select the builds that are most likely to fail for a particular change. Machine learning uses a large data set containing the results of packages on historical code changes to train the system. It learns from those previous code changes to come up with a build selection model, as shown in Figure 3.
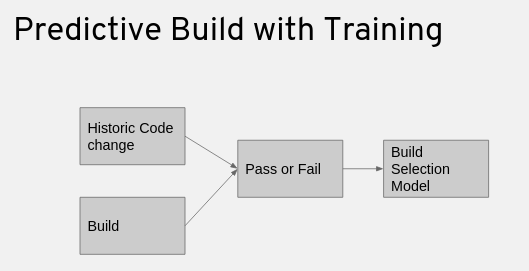
The system learns whether the build passes or fails based on the features from the previous code changes, as shown in Figure 4. Then, when the system analyzes new code changes, it applies the learned model to the code change. For any particular build, we can use the build selection model to predict the likelihood of a build failure.

Fail fast and recover fast with security scanning
Machine learning is also used in security scanning. For example, JFrog Xray is a security scanning tool that integrates with Artifactory to identify vulnerabilities and security violations before production releases. Artifact security scanning is an important step in the CI/CD pipeline. The idea is that we can use historical data to prioritize artifact scanning and scan the artifact that’s most likely to fail. This allows us to fail fast and recover fast.
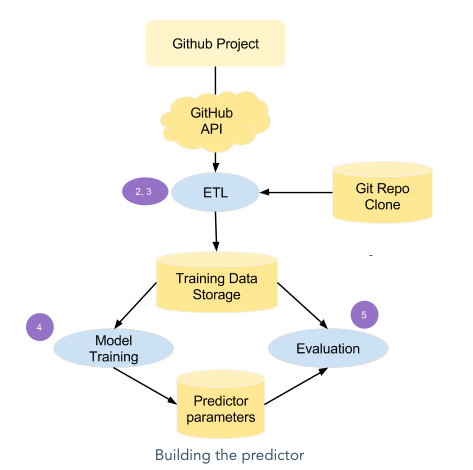
We can apply machine learning to develop a model that filters out unwanted pull requests (PRs). As developers, we work on large projects that have constant flows of pull requests. To make predictions about them, we need to create a model for the predictor. The steps to create a predictor are as follows:
- Define the relevant features.
- Gather data from data sources.
- Perform data normalizations.
- Train the models.
- Choose the best model.
- Evaluate the chosen predictor.
We use the extract, transform, and load (ETL) process to normalize our data, as shown in Figure 5.
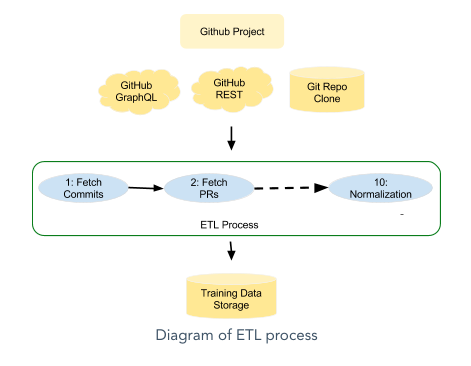
Figure 6 shows the steps to create the predictor.
Use machine learning for deployment validation
We can also apply machine learning to validating website deployments. Many websites have dependencies such as external components and third-party injection JavaScript. In this situation, the CI/CD deployment status can be successful while the third-party injected components might contain defects.
Using machine learning, we can capture the entire web page as an image and divide that image into multiple UX components. The division of the UX components can generate training and test data to feed into the learning model. With the model in place, we can test against any new UX components across different browser resolutions and dimensions by feeding the UX image components into the model. Incorrect images, text, and layouts will be classified as defects. We can then use the images to train a data model to discover defects.
Figure 7 shows an example of a deployment validation model. Once the training model is complete, we can use the same model to check for different pages on the website. Each image is classified with a score between 0 and 1. A score closer to 0 signifies a model prediction of a potential test case failure such as a UI defect. A score closer to 1 signifies a prediction of a test case that meets the quality criteria. A cutoff threshold determines a value below which the image has a potential UI defect.
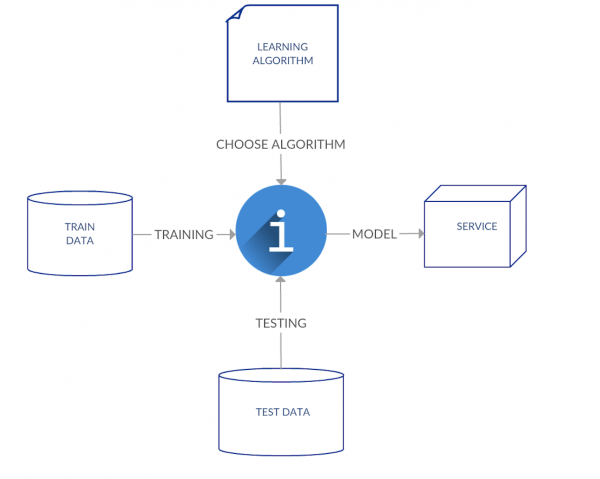
The supervised learning algorithm takes a set of training images as the training data. The learning algorithm is provided with the training data to learn about a desired function. The validation of the learning algorithm is used to compare with the test data. This process of learning from training data and validating against the test data is called modeling. The process of deciding the particular images into a pass or failed status is called classification.
Figure 8 shows an example of HTML injections by third-party JavaScript. We can leverage machine learning to validate HTML injections.

Figure 9 shows the corresponding HTML code inside the iframe object after the HTML injection.

Figure 10 shows a high-level view of the image segmentation and processing workflow using machine learning.

Use machine learning for alerting and monitoring
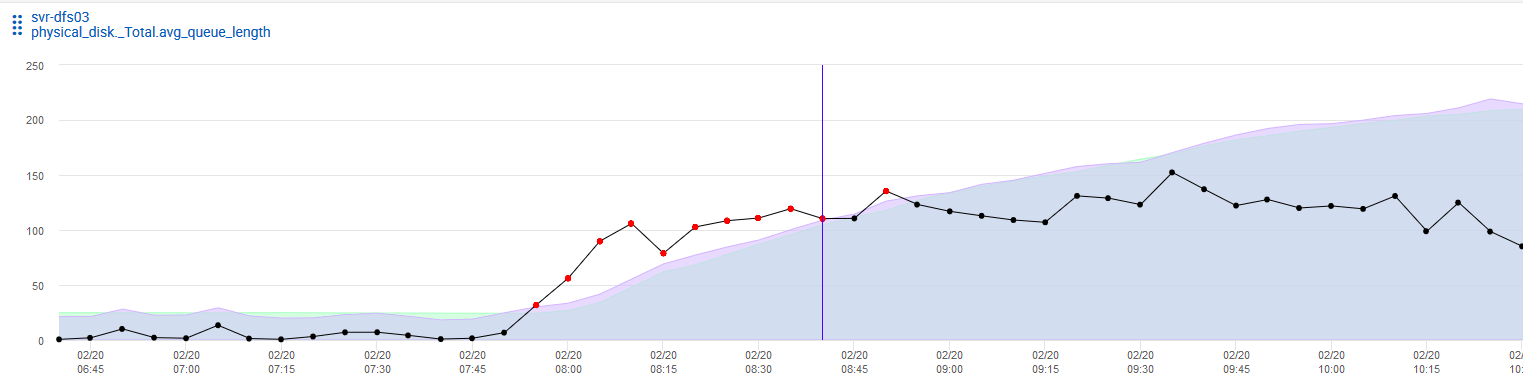
Machine learning can also be applied to alerting and monitoring. For example, machine learning can identify the disk space usage based on Prometheus alerts and predict when the disk space usage will hit the upper limit an hour in advance. Using machine learning, the system can send out notifications to the team early on potential production issues. We need to understand the key performance indicator (KPI) metrics for proactive production monitoring. The predictive disk outage requires making adjustments to the algorithms in production. The production data feeds back into the model to fine-tune the data set. The prediction accuracy will improve based on rules that have worked in the past.
Figure 11 is an example of disk usage monitoring using a machine learning prediction.
Use machine learning to select and prioritize tests
Traditionally, regression testing uses information extracted from build metadata to determine which tests to run on a particular code change. By analyzing build dependencies in the code, we can determine all the tests that need to be run based on dependencies. If a change happens to one of the low-level libraries, it is inefficient to rerun all of the tests on every dependency.
Machine learning also plays an important role in testing to improve efficiency. We can use machine learning to calculate the probability of a given test finding a regression with a particular code change. Machine learning can make an informed decision to rule out tests that are extremely unlikely to uncover an issue. Machine learning offers a new way to select and prioritize tests.
We can apply standard machine learning techniques on a large data set containing test results based on historical code changes. During training, the system learns a model based on features derived from previous code changes and test results of the corresponding code changes. When the system is analyzing new code changes, it applies the learned model to the code change. For any particular test, the model can predict the likelihood of the test finding defects in a regression. Then, the system can select the tests that are most likely to fail for a particular change and run those tests first. Often, we will encounter unstable tests that are not generating consistent results, or test outcomes that change from pass to fail although the code under test has not actually changed. In this situation, the model may not be able to predict test outcomes accurately. It is important to segregate the unstable tests for machine learning.
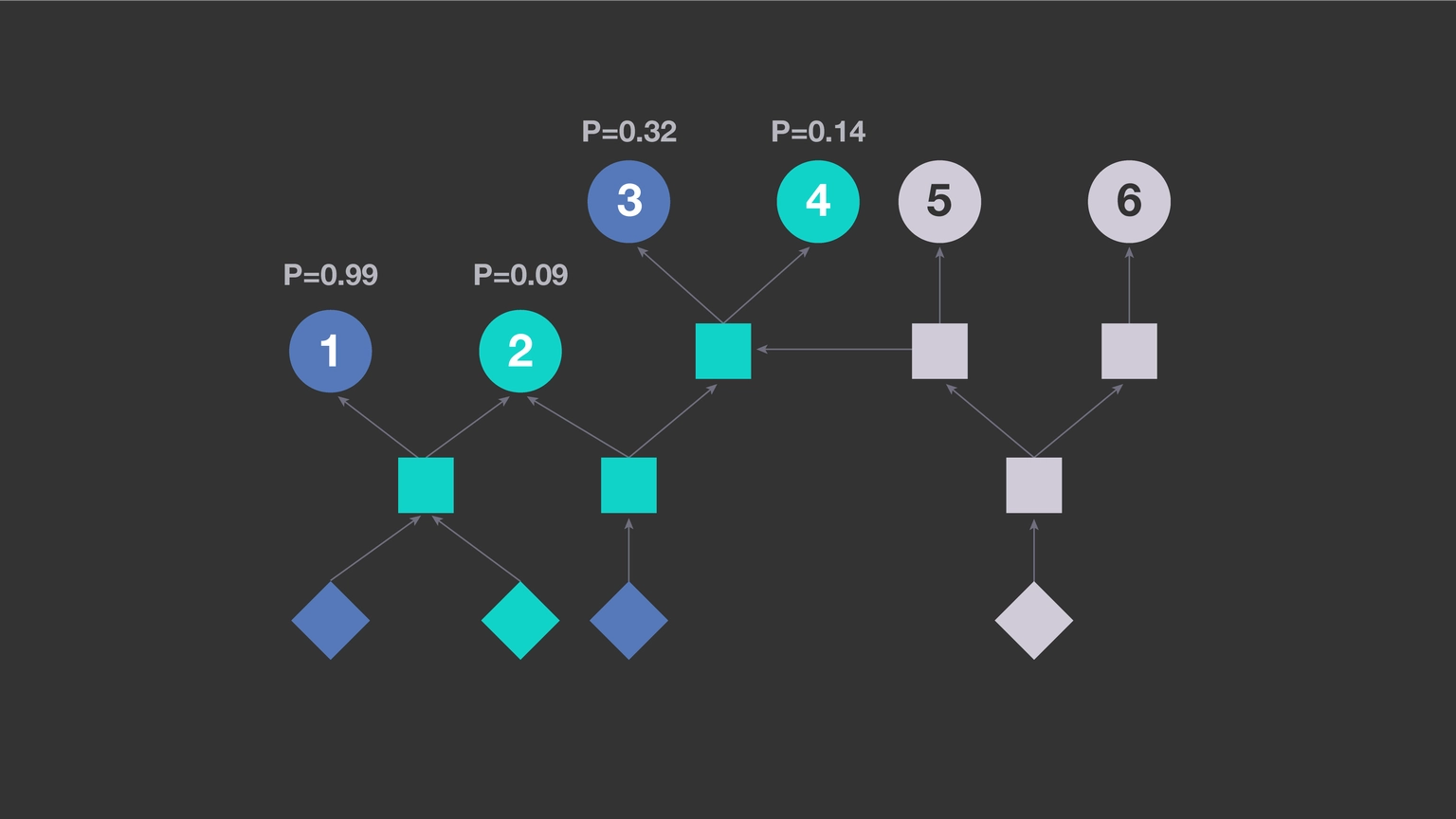
The test dependency diagram in Figure 12 is based on six test cases.
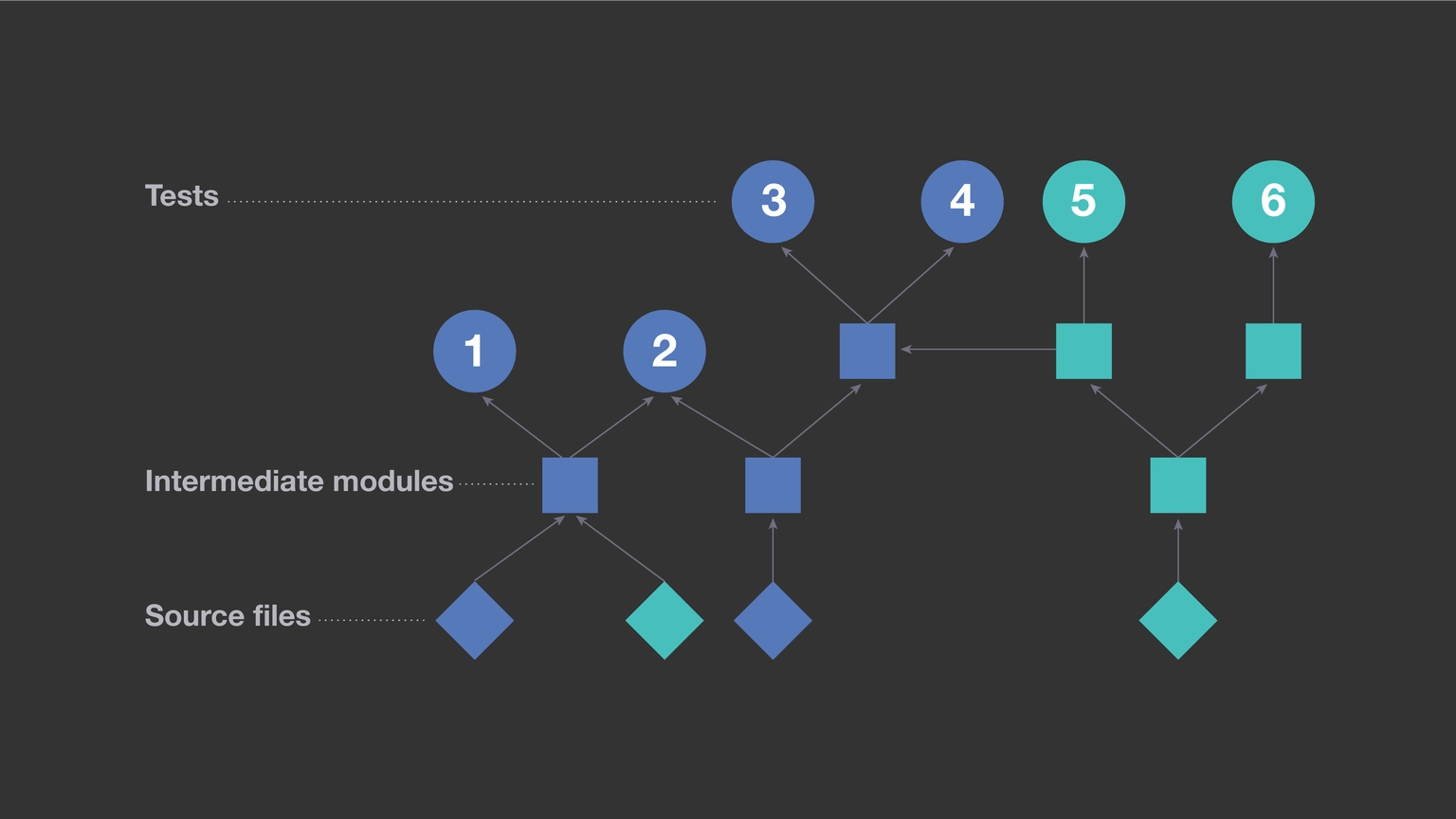
With predictive test case training, machine learning can predict the probability of failure for each test case and prioritize test cases using probability (see Figure 13).
Conclusion
In this article, we've looked at ways to apply machine learning to the GitOps life cycle to evaluate failures quickly. By combining machine learning with GitOps, developers can fix failures and commit code back to the CI/CD pipeline in an iterative fashion. This helps us eliminate the use of unnecessary computational resources. Many organizations face limitations when dealing with shorter release cycles. When the deployment results have external dependencies and are dynamic, GitOps combined with machine learning can help us make the best decisions and predictions based on historical data and generate predictive models and outcomes.
Last updated: August 26, 2022