In this article, I will describe my efforts to implement a faster interpreter for CRuby, the Ruby language interpreter, using a dynamically specialized internal representation (IR). I believe this article will interest developers trying to improve the interpreter performance of dynamic programming languages (e.g., CPython developers).
I will cover the following topics:
-
Existing CRuby interpreter and just-in-time (JIT) compilers for Ruby—MJIT, YJIT, and the MIR-based CRuby JIT compiler at the very early stages of development—along with my motivation to start this project and my initial expectations for the project outcome.
-
The general approach to performance improvement by specialization and the specializations used in my project to implement a faster CRuby interpreter. I will describe a new dynamically specialized internal representation called SIR, which speeds up the CRuby interpreter in the CRuby virtual machine (VM).
-
Implementation and current status.
-
Performance results in comparison with the base interpreter and other CRuby JIT compilers.
-
My future plans for this project and the significance of my work for developers.
The project motivation
About four years ago, I started a MIR project to address shortcomings of the current CRuby JIT compiler, MJIT. I started MIR as a lightweight, universal JIT compiler, which could be useful for implementing JIT compilers for Ruby and other programming languages.
MIR is already used for the JIT compilers of several programming languages.
Still, I realize that we can't use the current state of MIR to implement good JIT compilers for dynamic programming languages. Therefore, I've been working on new features. You can read about these features in my previous article, Code specialization for the MIR lightweight JIT compiler. In brief, these features include:
- A generalized approach of propagation of dynamic properties of source code based on lazy basic block versioning and generation of specialized code according to the properties
- Trace generation and optimization based on basic block cloning
- A metatracing MIR C compiler, the project's ultimate goal
Implementation of these features has taken me many years. The recent success of Shopify's YJIT compiler made me rethink my strategy and find a faster way to implement a MIR-based JIT compiler for CRuby.
To implement a decent MIR-based JIT compiler, I decided earlier to develop some features with a design specific to CRuby. I use dynamically specialized instructions for the CRuby VM and generate machine code from the instructions using the MIR compiler in its current state.
Implementing a dynamically specialized IR and an interpreter for it is beneficial, even without a JIT compiler. The resulting design permits the implementation of a faster CRuby without the complexity of JIT compilers and their portability issues.
YJIT is a very efficient JIT compiler, so I have been assessing its features and asking what other features could make a compiler better.
It is essential to start by understanding how much code is covered by a type of optimization. Some optimizations are limited to a single VM instruction.
Most optimizations work within a basic block, a group of instructions that run sequentially without internal loops or conditional statements. In Ruby, each basic block is enclosed within braces and is often the body of an innermost loop or an if statement. Optimizations that span more than a single basic block are much more difficult.
For each stack instruction in the VM, YJIT currently generates the best machine code seen in the field. YJIT generates even faster code than the leading open source C compilers, GCC and LLVM Clang, for a single VM instruction in the interpreter.
Note: YJIT was initially written in C but was rewritten in Rust to simplify the porting of YJIT to new architectures. The Rust implementation employs abstractions provided currently by the Shopify Ruby team. In my opinion, the best tool to implement a portable YJIT would have been the DynASM C library.
Another compiler technique used by YJIT is basic block versioning, a powerful technique for dynamically executed languages such as Python and Ruby. I'll describe basic block versioning in the upcoming section, Lazy basic block versioning. The essential idea is that many versions, each with different compiler instructions, exist for each basic block. Some versions are specialized for certain conditions, such as particular data types, and are more efficient than the non-specialized versions when the right conditions hold. The compiler can use the more efficient versions when possible and fall back on less efficient versions under different conditions.
But YJIT's code generation does not span multiple VM instructions. Register transfer language (RTL) is another technique available to compilers, which optimizes code across several stack VM instructions. So I started my new project hoping that, if I implement RTL and use basic block versioning similar to YJIT for some benchmarks, I can match the performance of YJIT even in the interpreter.
I will reveal what I achieved later in this article.
Code specialization
I have mentioned "code specialization" several times, but what is specialization? The Merriam-Webster dictionary provides the following definition of the word which is suitable for our purposes: to design, train, or fit for one particular purpose.
If we generate code optimized for a particular purpose that happens to be a frequent use case, our code will work faster in most cases. Specialization is one common approach to generating faster code. Even static compilers generate specialized code. For instance, they can generate code specialized for a particular processor model, such as a matrix multiplication that fits a particular size of processor cache.
Specialized code also exists in CRuby. For example, the CRuby VM has specialized instructions for calling methods that operate on numbers, the most frequently used data types. The instructions have specialized names such as opt_plus.
The compiler can accomplish code specialization statically or dynamically during program execution. Dynamic specialization adds execution time but is hopefully more efficient because interpreters and JIT compilers have more data during the run to help select a particular case for specialization. That is why JIT compilers usually do more specialization than static compilers.
You can specialize speculatively even when you cannot guarantee that particular conditions for specialization will always be true. For instance, if a Ruby variable is set to an integer once, you can safely speculate that future assignments to that variable will also be integers. Of course, this assumption will occasionally prove untrue in a dynamically typed language such as Ruby.
Therefore, during speculative specialization, you need guards to check if the initial conditions for specialization still hold true. If these conditions are not true, you switch to less efficient code that does not require those conditions for correct execution. Such code switching is commonly called deoptimization. Guards are described in the upcoming sections, Lazy basic block versioning and Profile-based specialization.
The more dynamic a programming language, the more specialization and the more speculative specialization you need to achieve performance close to static programming languages.
8 Optimization techniques
The following subsections describe the eight techniques I have added to my interpreter and MIR-based JIT compiler.
- Dynamically specialized CRuby instructions
- RTL code instructions
- Hybrid stack/RTL instructions
- Type-specialized instructions
- Lazy basic block versioning
- Profile-based specialization
- Specialized iterator instructions
- Dynamic flow of specialized instructions
1. Dynamically specialized CRuby instructions
All the specialization I am implementing for CRuby is done dynamically and lazily. Currently, I optimize only on the level of a basic block.
I use specialized hybrid stack/RTL instructions. This kind of specialization could be done at compile time, but my interpreter does it lazily as part of a larger technique of generating several different specialized basic blocks. Laziness helps to save memory and time spent on RTL generation. I will explain later why I use hybrid stack/RTL instructions instead of pure RTL.
I also generated type-specialized instructions. This can be done by lazy basic block versioning, invented by Maxime Chevalier-Boisvert, and used as a major optimization mechanism in YJIT. This optimization is cost-free, and no special guards are needed for checking the value types of instruction input operands. Type specialization is also based on profiling program execution. In this case, the interpreter needs guards to check the types of instruction input operands. Such type of specialization helps to improve cost-free type specialization even further.
Other specializations are based on profile information. Additionally, I included specialized instructions for method calls and accesses to array elements, instance variables, and attributes. The most interesting case is iterator specialization, which I will describe later.
2. RTL code instructions
CRuby uses stack instructions in its VM. Such VM instructions address values implicitly. We can also use VM instructions addressing values explicitly. A set of such instructions is called a register transfer language (RTL).
Here is an example of how the addition of two values is represented by stack instructions and by the RTL instructions generated by my compiler. The number sign (#) is used to start a comment in both languages:
| Stack instructions | RTL instructions |
|
getlocal v1 # push v1 getlocal v2 # push v2 opt_plus # pop v1 and v2 push v1 + v2 setlocal res # pop stack value and assign it to res |
sir_plusvvv res, v1, v2 # assign v1 + v2 to res |
As a rule, RTL code contains fewer instructions than stack-based instructions, and as result spends less time in interpreter instruction dispatch code. But RTL sometimes spends more time in operand decoding. More importantly, RTL code results in less memory traffic, because local variables and stack values are addressed directly by RTL instructions. Therefore, stack pushes and pops of local variable values are not as necessary as they are when using stack instructions.
In many cases, CRuby works with values in a stack manner. For example, when pushing values for method calls. So pure RTL has its own disadvantages in such cases and might result in larger code that decodes operands more slowly. Another Ruby-specific problem in RTL lies in implementing fast addressing of Ruby local variables and stack values. Figure 1 shows a typical frame from a Ruby method.
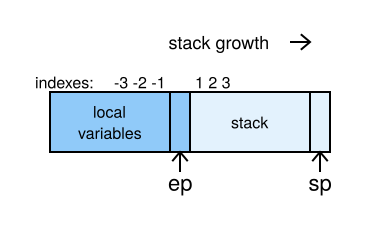
Addressing values in this kind of stack frame is simple. You just use an index relative to ep (environment pointer): Negative indices for local variables and positive indices for stack values.
Unfortunately, a method's frame could also look like Figure 2.
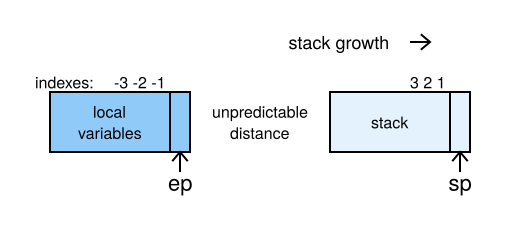
For this kind of frame, you need to use ep for local variables and sp (stack pointer) for the stack. Other ways of addressing could be used, but they all depend on addressing local and stack variables differently. This means a lot of branches for addressing instruction values.
Still, I used RTL about four years ago, and at that time it gave about a 30% improvement on average on a set of microbenchmarks.
3. Hybrid stack/RTL instructions
Based on my previous experience, I modified my old approach of using RTL and started to use hybrid stack/RTL instructions. These instructions can address some operands implicitly and others explicitly.
RTL instructions are generated only on the level of a basic block, and only lazily on the first execution of a basic block. Figure 3 shows the RTL instructions I added.
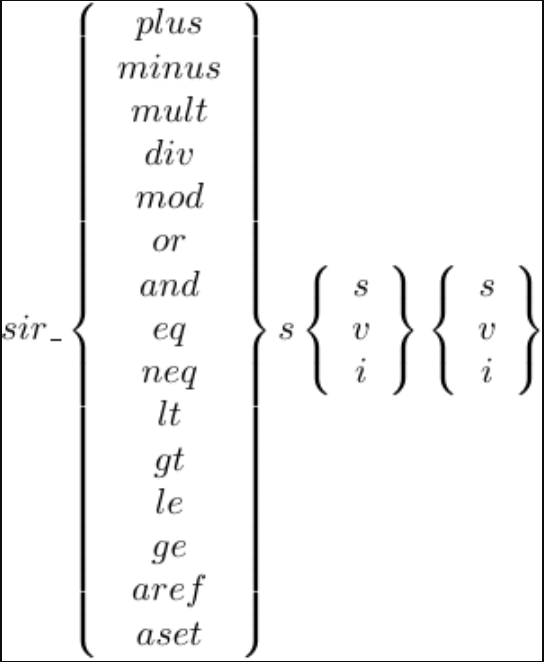
Here, the suffix (final letter) holds the following meanings:
s: The value is on the stack.v: The value is in a local variable.i: The value is an immediate operand.
Some combinations of suffixes are not used. For example, the suffix sss is not used because an instruction with such a suffix would actually be an existing CRuby stack instruction.
It seems that adding many new VM instructions might result in worse code locality in the interpreter. But in practice, the benefits of reduced dispatching and stack memory traffic outweigh code locality problems. In general code, locality is less important than data locality in modern processors. Just the introduction of hybrid stack/RTL instructions can improve the performance of some benchmarks by 50%.
4. Type-specialized instructions
Integers in the CRuby VM are represented by multi-precision integers or by fixnum, a tagged integer value that fits in one machine word. Floating-point numbers are represented where possible by tagged IEEE-754 double values called flonum, and otherwise by IEEE-754 values in the CRuby heap.
Many CRuby VM instructions are designed to work on primitive data types like a fixnum. The instructions make a lot of checks before executing the actual operation. For example, opt_plus checks that input data is fixnum and that the Ruby + operator is not redefined for integers. If the checks fail, a general + method is called.
Type-specialized instructions allowed me to remove the checks and the call code. The optimization resulted in faster and slimmer VM instructions and better interpreter code locality. The new type-specialized instructions are shown in Figure 4.
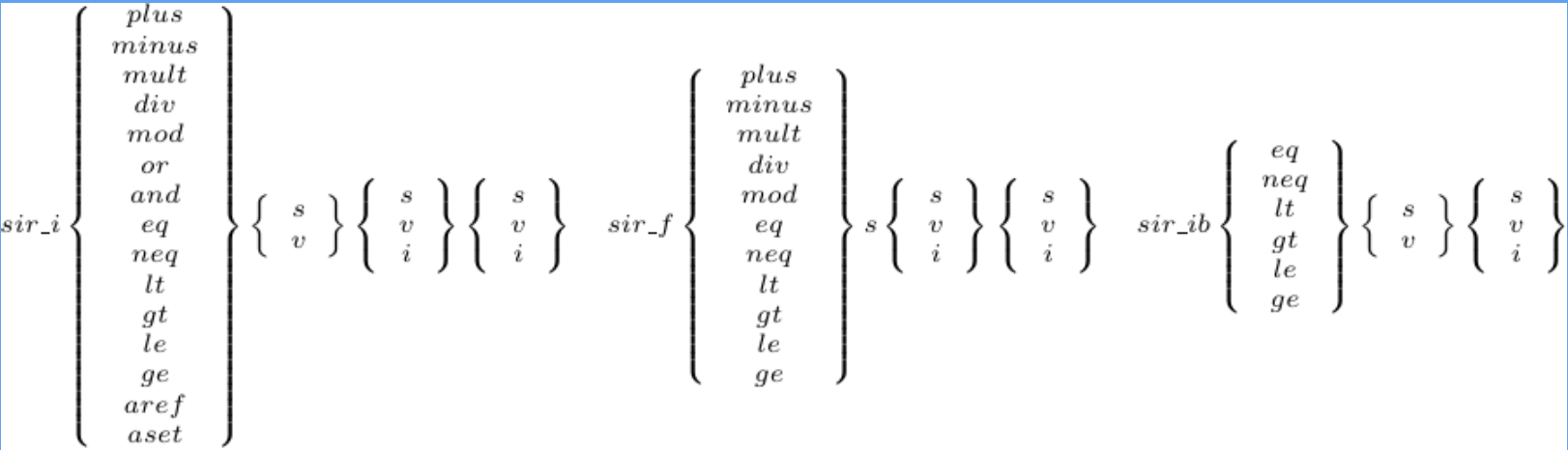
The prefix takes on the following meanings:
sir_i: Denotes instructions specialized for fixnum (integers).
sir_f: Denotes instructions specialized for flonum (floating-point numbers).
sir_ib: Used for branch and fixnum compare instructions.
To guarantee that type-specialized instructions are passed data of the expected types, lazy basic block versioning can be used.
The type-specialized instructions can be also generated from the profile information. In this case, type guards guarantee data of the expected types.
If an exceptional event prevents the remainder of a basic block from executing, the interpreter deoptimizes code by switching to RTL code for the basic block, which is not type-specialized. An example of an exceptional event could be a fixnum overflow, which requires a multi-precision number result instead of the expected fixnum. Hybrid stack/RTL and type-specialized instructions are designed not to do any instruction data moves before the switch, which would require pushing variable values on the stack.
The same deoptimization happens if a standard Ruby operator, such as integer +, is redefined. The deoptimization removes all basic block clones containing type-specialized instructions for this operation, because there is a tiny probability that these basic block clones will be used in the future.
Instructions specialized for flonum values hardly improve interpreter performance, because most of the instruction execution time is spent tagging and untagging flonum values, requiring many shifts and logical operations. Therefore, I included the instructions specialized for flonum values mostly for a future MIR-based JIT compiler, which will remove redundant floating-point number tagging and untagging.
5. Lazy basic block versioning
This technique is easiest to explain by an example. Take the following while loop:
while i < 100 do
i += 1
end
Figure 5 illustrates basic block versioning for this loop.
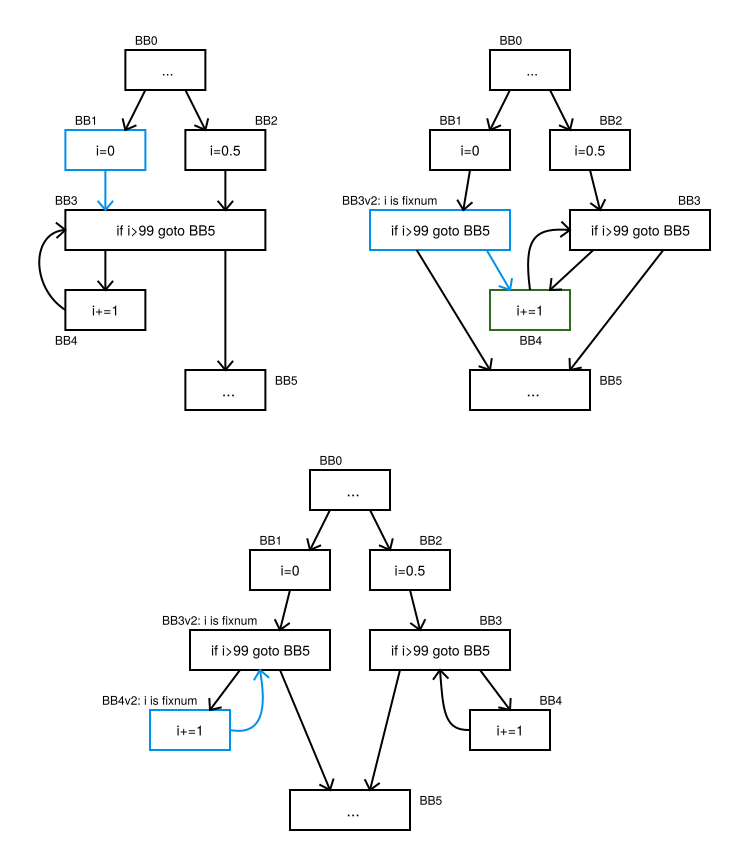
Upon its first encounter with the basic block, the interpreter doesn't know the types of values on the stack or in variables. But when we execute BB1 for the first time (see the first diagram), we can easily figure out that the value type of i became fixnum.
In the top left diagram, the successor of BB1 is BB3 and there is only one version of BB3, which has no knowledge of variable value types. So we clone BB3 to create BB3v2, in which the value type of i is always fixnum. We make BB3v2 a successor of BB1 (see the second diagram) and start executing BB3v2.
From BB3v2, since we haven't completed the loop, we go to BB4. No variable value is changed in BB3v2. So at the end of BB3v2 the value type of i is still fixnum. Therefore, we can create BB4v2 and make it a successor of BB3v2. Because we know that the value type of i is fixnum at the beginning of BB4v2, we can easily deduce that the type of i at the end of BB4v2 is also fixnum. We need a version of BB4v2's successor in which the type of i is fixnum. Fortunately, such a version already exists: BB3v2. So we just change the successor of BB4v2 to BB3v2 (see the third diagram) and execute BB3v2 again.
In short, knowing the type of i permits the interpreter to specialize instructions in BB3v2 and BB4v2.
As you can see, we create basic block versions only when a preceding block is actually executed at run time. This is why such basic block versioning is called lazy. Usually, we create only a few versions of each basic block. But in pathological cases (which can be demonstrated) a huge number of versions can be created. Therefore, we place a limit on the maximum number of versions for one basic block. When we reach this number, we use an already existing basic block version (usually a version with unknown value types) instead of creating a new one.
Basic block versioning can be also used for other specialization techniques besides type-specialization.
6. Profile-based specialization
When the interpreter can't find out the input data types from basic block versioning (e.g., when handling the result of a polymorphic type method call), we insert a sir_inspect_stack_type or sir_inspect_type profiling instruction to inspect the types of the stack values or local variables. After the number of executions of a basic block version reaches some threshold, we generate a basic block version with speculatively type-specialized instructions for the data types we found, instead of profiling instructions. Figure 6 shows the format of names of speculatively type-specialized instructions.
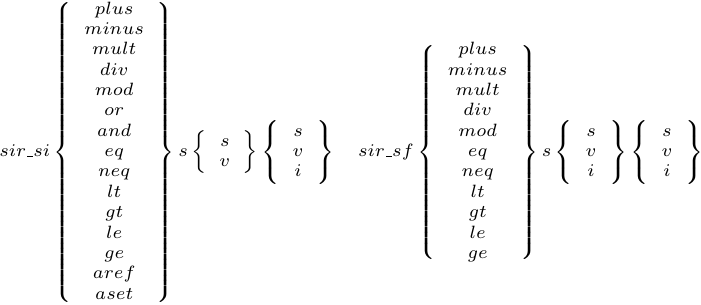
The speculative instructions check the value types of the operands. If the operand doesn't have the expected type, the instruction switches to a non-type specialized version of the basic block.
Figure 7 shows some possible changes made from sir_inspect_type, used for profiling the types of local variable values. Instructions sir_inspect_type, sir_inspect_fixtype, and sir_inspect_flotype are self-modified. Depending on the types of the inspected values at the profiling stage, instead of sir_inspect_type we will have sir_inspect_fixtype (if we observed only fixnum types), sir_inspect_flotype (if we observed only flonum types) or nop in all other cases. After the profiling stage we removes all inspect instructions and nops and can generate speculative instructions from non-type-specialized RTL instructions affected by the inspect instructions, e.g. we can generate speculative instruction sir_simultsvv instead of non-type-specialized RTL instruction sir_multsvv if we observed that the instruction input values were only of fixnum type.
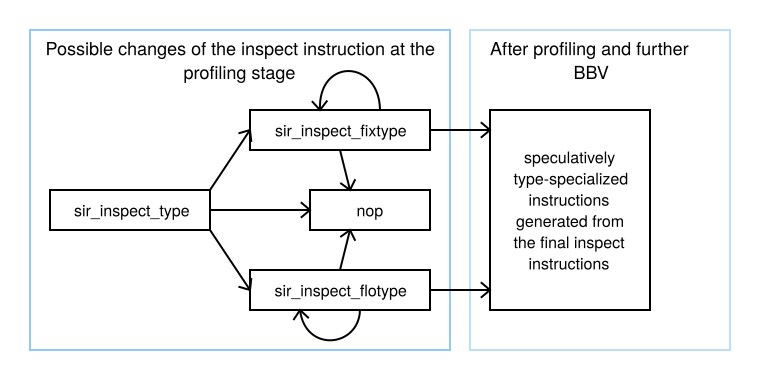
The speculative instructions check data types lazily, only when we do something with the data except data moves. Speculatively type-specialized instructions permit the interpreter to use more of the new non-speculative type-specialized instructions in a basic block version. In these cases, the speculative instructions act as type guards for values used in the subsequent instructions.
Additionally, based on the profile information, the original VM call instructions can be specialized to instructions for C function calls, calls to an iseq (a sequence of VM instructions), or accesses to instance variables.
7. Specialized iterator instructions
Many standard Ruby methods are implemented in C. Some of these methods accept a Ruby block represented by an iseq and behave as iterators.
To execute the Ruby block for each iteration, the C code calls the interpreter. This is a very expensive procedure involving a call to setjmp (also used to implement CRuby exception handling). We can avoid invoking the interpreter by replacing the method call with specialized iterator instructions:
sir_iter_start start_func
sir_cfunc_send => Lcont: sir_iter_body Lexit, block_bbv, cond_func
sir_iter_cont Lcont, arg_func
Lexit:
The iterator instructions are:
-
sir_iter_start start_funcstart_funcchecks the receiver type and sets up block arguments. -
sir_iter_body exit_label, block_bbv, cond_funccond_funcfinishes the iteration or callsblock_bbv. -
sir_iter_cont cont_label, arg_funcarg_funcupdates block arguments and permits a goto tocont_label.
Iterator instructions keep their temporary data on the stack. An example of such data is the current array index for an array each method.
Currently, iterator instructions are implemented only for the fixnum times method and for the range and array each methods. Adding other iterators is easy and straightforward. Usually, you just need to write three very small C functions.
Such specialized iterator instructions can significantly improve performance of Ruby's built-in iterator methods.
8. Dynamic flow of specialized instructions
CRuby's front-end, just like the one in CRuby's original implementation, compiles source code into iseq sequences. For each iseq we also create a stub, an instruction that is executed once and provides the starting point for executing the iseq.
Most executions of basic blocks can rely on assumptions we make about data types during compilation and execution. If we find, during execution, that our speculative assumptions do not hold, we switch back to non-type-specialized hybrid stack/RTL instructions.
For the speculatively type-specialized instructions, the switch can happen when the input value types are not of the expected types. An example situation that violates a speculative assumption for type-specialized instructions is an integer overflow that switches the result type from a fixnum to a multi-precision number.
Figure 8 shows the flow through a basic block. The downward arrows show the flow that takes place so long as assumptions about data types are valid. When an assumption is invalidated, the path shown by the upward arrows is taken.
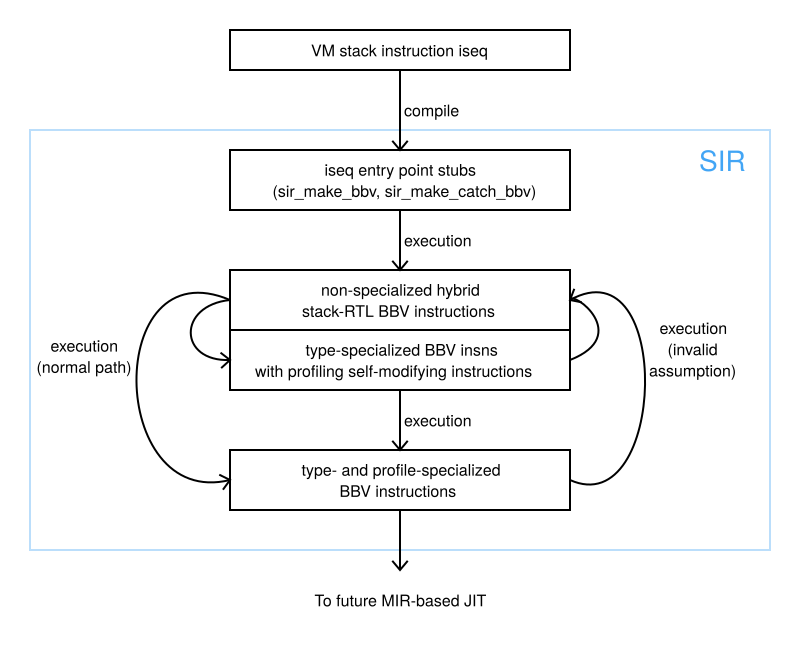
Execution of a stub creates hybrid stack/RTL instructions for the first basic block of the iseq. At this point, we also generate type-specialized instructions from type information that we know, and profile instructions for values of unknown type. These type-specialized instructions will be the new execution starting point of the iseq during further iterations.
After that, execution continues from the new type-specialized instructions in the basic block. Possible continuations of the basic block at this point are also stubs for successor basic blocks. When the stub of a successor basic block runs, we create hybrid stack/RTL instructions and instructions specialized by type information collected from types in the predecessor basic block. Profiling instructions are also added here. Execution then proceeds with the new basic blocks.
After a specified number of executions of the same basic block, we generate type-specialized instructions and instructions specialized from the collected profile information. And this is now the new starting point of the basic block. The type-specialized and profile-specialized basic block is also a starting point for the MIR-based JIT compiler I am working on. The current MIR-based compiler generates code from the type-specialized and profile-specialized instructions of one basic block. In the future, the compiler will also generate code from the type-specialized and profile-specialized instructions of the entire method.
Current status of the implementation
My interpreter and MIR-based JIT compiler that use the specialized IR can be found in my GitHub repository. The current state is good only for running the benchmarks I discuss later. Currently, specialized IR generation and execution is implemented in about 3,500 lines of C code. The generator of C code for MIR is about 2,500 lines. The MIR-based JIT compiler needs to build and install the MIR library, whose size is about 900KB of machine code. Although his library can be shrunk.
To use the interpreter with the specialized IR, run a program with the --sir option. There is also an --sir-max-versions=n option for setting the maximum number of versions of a basic block.
To use the interpreter with the specialized IR and MIR JIT compiler, run a program with the --mirjit option.
You can also enable the --sir-debug and --mirjit-debug debugging options, but please be aware that the debugger output, even for a small Ruby program, will be pretty big.
Benchmarking the faster interpreter
I have benchmarked the faster interpreter against the base CRuby interpreter, YJIT, MJIT, and the MIR-based JIT compiler using the following options:
- Interpreter with SIR:
--sir - YJIT:
--yjit-call-threshold=1 - MJIT:
--jit-min-calls=1 - SIR+MIR:
--mirjit
The run time of each benchmark varies from half a minute to a couple of minutes. The run-time options for each JIT compiler are chosen to generate machine code as soon as possible and thus get the best result for that compiler.
I did the benchmarking on an Intel Core i7-9700K with 16GB memory under Linux Fedora Core 32, using my own microbenchmarks which can be found in the sir-bench directory of my repository and Optcarrot. Each benchmark was run three times and the best result was chosen.
Note that the MIR-based JIT compiler is in the very early stage of development, and I am expecting significant performance improvements in the future.
Results from microbenchmarks
Figure 9 shows the wall times for various microbenchmarks.
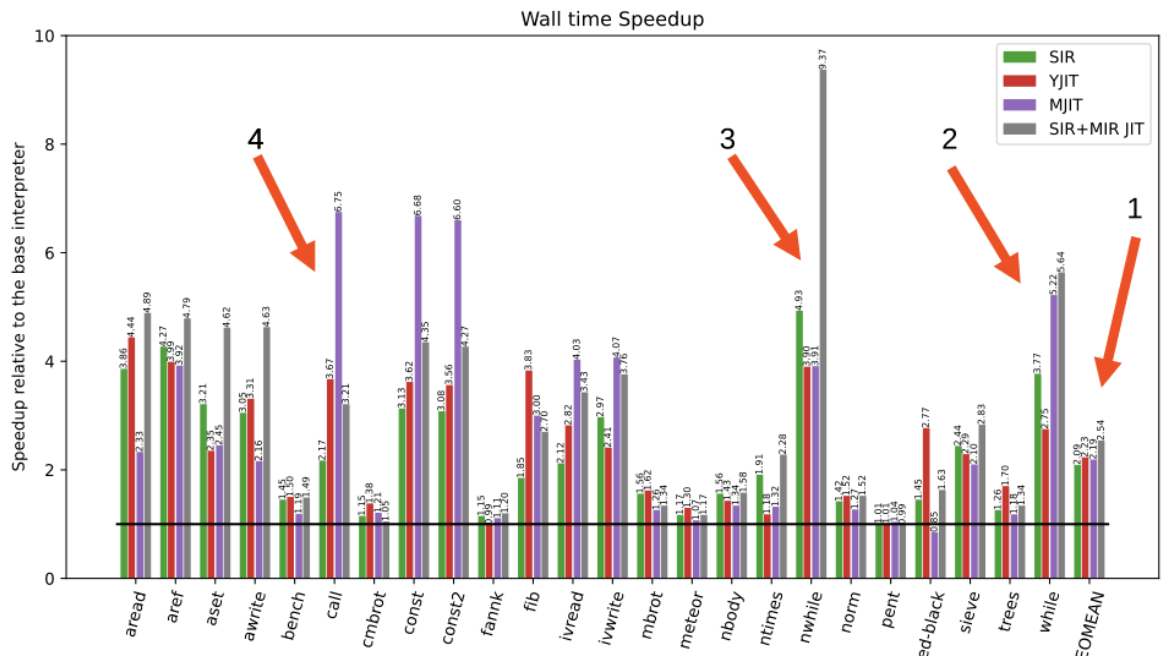
The following points explain some of the results:
-
On Geomean, my new interpreter achieved 109% of the performance of the base CRuby interpreter, but was 6% slower than YJIT.
-
RTL with type specialization makes the
whilebenchmark run faster than YJIT. Using RTL decreases the number of executed instructions per iteration from 8 (stack instructions) to 2 (RTL instructions) and removes 5 CRuby stack accesses. -
Iterator specialization permits my interpreter to execute the
ntimes(nested times) benchmark without leaving and entering the majorvm_exec_coreinterpreter function. Avoiding that switch results in better code performance. As I wrote earlier, entering the function is very expensive, as it requires a call to thesetjmpC function. -
Method calls are where the interpreter's specialization does not work well. YJIT-generated code for the
callbenchmark works twice as fast as my interpreter with the specialized IR. YJIT generates code that is already specialized for the call's particular characteristics. For instance, YJIT can reflect the number of arguments and the local variables of the called method. I could add call instructions specialized for these parameters too, but doing so would hugely increase the number of specialized instructions. So I decided not to even try this approach, especially as such specialization will be solved by the MIR-based JIT compiler.
People often measure only wall time for benchmarks. But CPU use is important too. It reflects how much energy is spent executing the code. CPU time improvements are given in Figure 10.
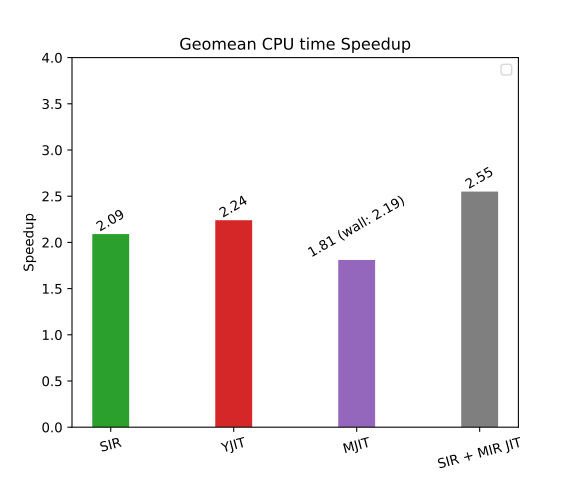
Differences in CPU usage are comparable to differences in wall time for the microbenchmarks, except for MJIT. MJIT generates machine code using GCC or LLVM in parallel with Ruby program execution. GCC and LLVM do a lot of optimizations and spend a lot of time in them.
YJIT-based and MIR-based JIT compilers do not generate code in parallel. When they decide to JIT-compile some VM instructions, code execution stops until the machine code for these instructions is ready.
Figure 11 shows the maximum resident memory use of my fast interpreter and different JIT compilers, relative to the basic interpreter.
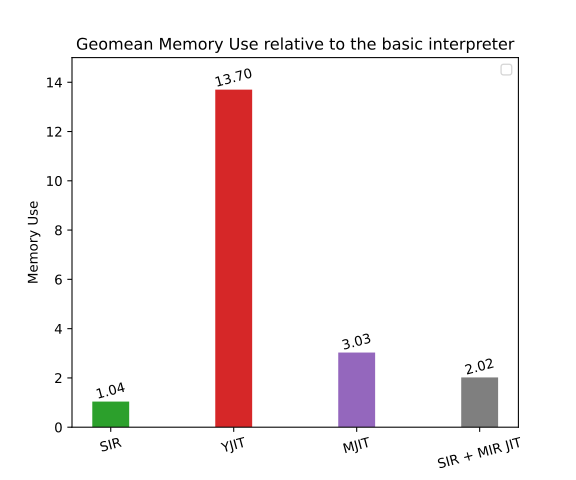
YJIT reserves a big pool of memory for its work. This memory is often not fully used. I assume this YJIT behavior can be improved.
Optcarrot benchmark results
Optcarrot, a Nintendo game computer emulator, is a classic benchmark for Ruby. Figure 12 shows the best frame per second (FPS) values when 3,000 frames are generated by Optcarrot.
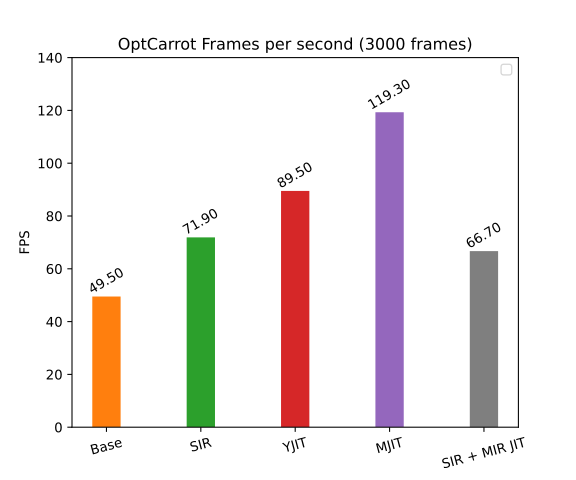
The specialized IR shows a 45% improvement over the basic interpreter.
In the optimized version of Optcarrot (Figure 13), a huge method is generated before execution. Basically, the method is a substitute for aggressive method inlining. Because there are a lot fewer method calls, for which specialization in the interpreter is not as good as for JIT compilers, the interpreter with the specialized IR generates the second-best result, right after the MIR-based JIT compiler.
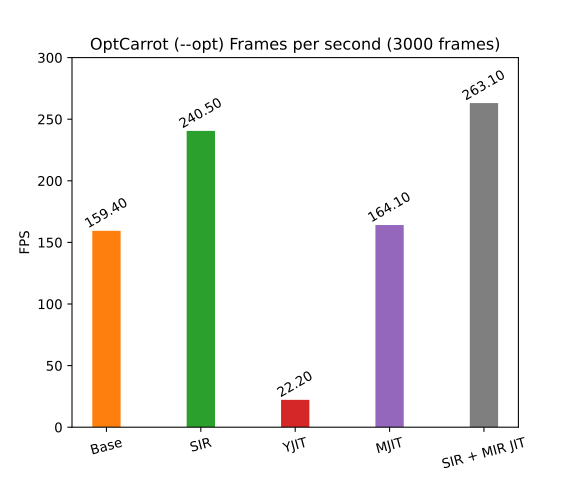
YJIT behavior is the worst on this benchmark. I did not investigate why YJIT has such low performance in this case. I have heard that the reason might be that YJIT did not implement the opt_case_dispatch instruction used by the optimized Optcarrot.
Although MJIT produces a decent FPS result, it takes forever to finish the benchmark. Running with MJIT, Ruby terminates only when compilation finishes for all methods currently being compiled by GCC or LLVM. This trait is a specific limitation of the current parallel MJIT engine. Because the huge method requires a lot of time for GCC to compile, the method in this benchmark is actually being executed by the interpreter. The benchmark finishes in a reasonable amount of time, but MJIT is still waiting for the method compilation to finish, even though the generated machine code is never used.
The significance of this prototype for Ruby and Python
The faster CRuby interpreter described in this article is only a very early prototype. Much needs to be added, and there are still many bugs. I am going to finish the work this year and continue my work on a MIR-based CRuby JIT compiler using the specialized IR. There are still many bugs to fix in the JIT compiler and a lot of work must be done to generate better code.
The specialization described here is useful for developers who already use classical approaches to speed up dynamic programming language interpreters and now want to achieve even better interpreter performance. Currently, I consider the specialized IR and the MIR-based CRuby JIT compiler more as research projects for me than as candidates for production use. The enhancements in the projects demonstrate what can be accomplished with the MIR project.
What's next?
Because there is too much technical debt in my different code bases, I probably cannot provide maintenance and adaptation of the code for future CRuby releases. Anyone can use and modify my code for any purpose. I welcome such work. I will provide help where I can, but unfortunately, I cannot commit to this work. However, I am fully committed to maintaining and improving the MIR project.
Currently, CPython developers are working on speeding up their interpreter. Some techniques described here (particularly RTL and basic block versioning) are not used in their project. But these techniques might prove even more profitable than CRuby because CPython uses reference counts for garbage collection. It may be easier to implement the techniques I developed in CPython. Although CPython supports concurrency, it does not have real parallelism as CRuby does.
You can comment below if you have questions. Your feedback is welcome. Developers can also get some practice with hands-on labs in Developer Sandbox for Red Hat OpenShift for free.
