As an Ansible Lightspeed engineer, my team works on the cloud service that interacts with Watson Code Assistant large language models for Ansible task generation. Curious to learn more about the mechanics of training such a model, I set out to create my own, very basic Ansible tasks model. I decided to do this using Red Hat OpenShift Data Science, which made it easy to configure and launch an environment pre-configured with everything I needed to train my model. I’ll walk through the steps I took here.
Training a basic Ansible tasks model for fun over a weekend on a single GPU would be an impossible task if not for the concept of “transfer learning.” Thanks to transfer learning, we can take an existing pre-trained model and fine-tune it on something new. In this case, we will use the HuggingFace Transformers API to fine-tune the BigCode SantaCoder model. SantaCoder is used for code generation and is trained on Python, Java, and JavaScript. Because Ansible playbooks are YAML, we’ll first fine-tune the model on YAML and then fine-tune it on Ansible content specifically.
To complete the steps below, you will need to ensure you have sufficient, dedicated compute available on your cluster. I provisioned a new g5.8xlarge AWS EC2 instance to support this project.
Creating an OpenShift Data Science project
To get started, we’ll create a data science project in Red Hat OpenShift Data Science. From the OpenShift Data Science dashboard, click Data Science Projects and then Create data science project. Provide a name, such as Ansible Playbooks Model, and Create.
From the newly created project, click Create workbench. You will see the Create workbench page shown in Figure 1.
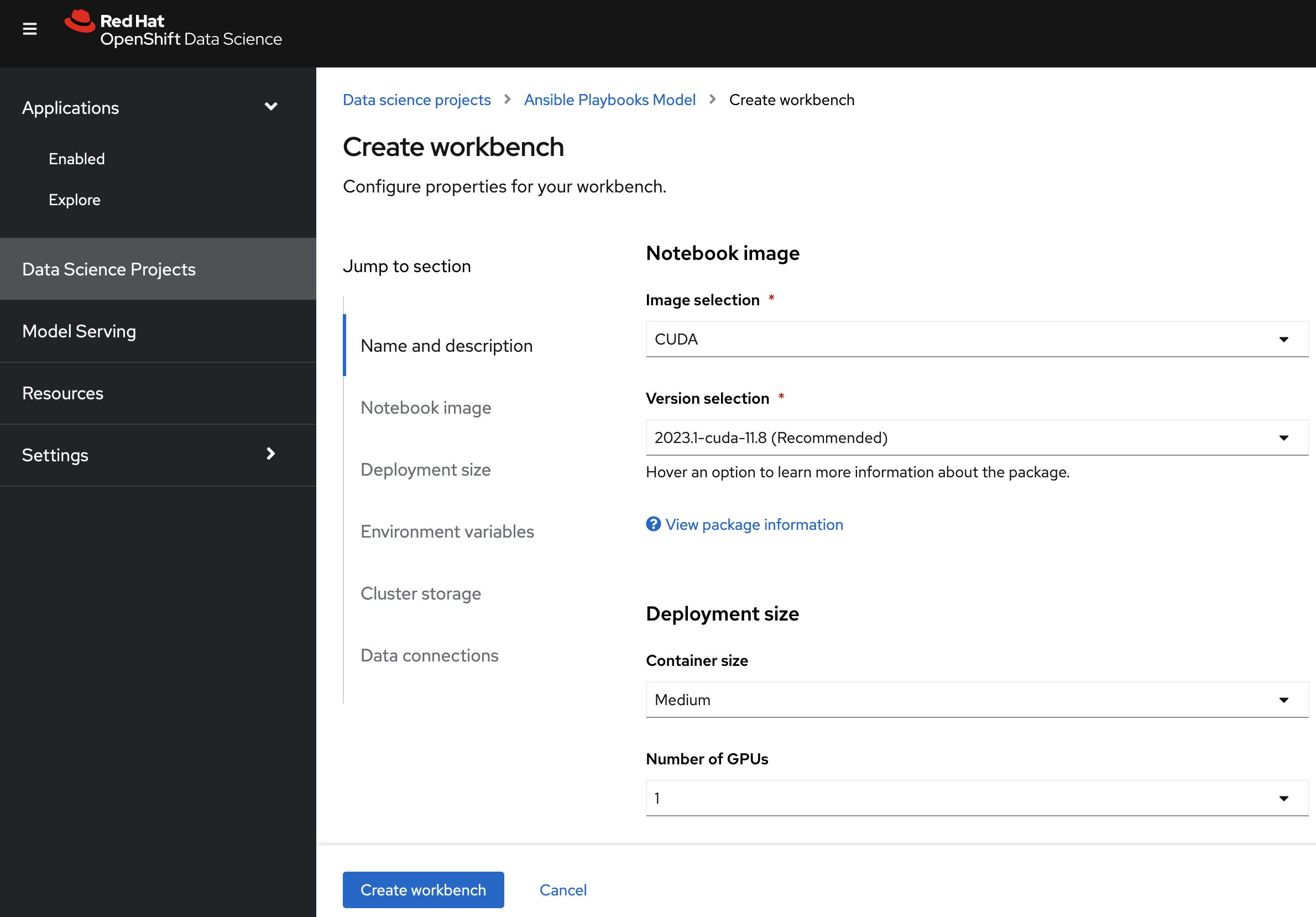
Create your workbench with the following parameters (order of parameters may vary with your OpenShift Data Science version):
- Image selection: CUDA
- Deployment size>Container size: Medium
- Deployment size>Number of GPUs: 1
- Persistent storage size: 200 GiB
- Environment variables>Secret>Key/value:
HUGGINGFACE_TOKEN
For the HUGGINGFACE_TOKEN environment variable value, retrieve your HuggingFace access token from https://huggingface.co/settings/tokens. You will need to be authenticated with HuggingFace in order to use The Stack dataset.
Once created, launch the workbench to begin fine-tuning.
Note: As you are working through the steps below, you might find at some points that your notebook fails with Out of Memory errors. I worked around this by shutting down the kernel of any notebooks I was not currently using.
Fine-tuning on YAML
With your workbench configured and launched, it is time to fine-tune SantaCoder on YAML. For this, we will use the YAML subset of The Stack dataset from BigCode. You can find two great code samples for fine-tuning SantaCoder in the santacoder-finetuning repo and this Google Colab, which fine-tunes on shell/bash. The GitHub repository provided for use with this tutorial is based on these two samples.
To clone the sample repository, click the Git icon in the OpenShift Data Science workbench left sidebar and click Clone a Repository. Specify the following URL and click Clone: https://github.com/robinbobbitt/santacoder-ansible.git
With the repo cloned, double-click into the santacoder-ansible folder, then double-click the train-yaml.ipynb Jupyter notebook file. You should see the contents of the santacoder-ansible repo in your File Browser and the Fine-tune SantaCoder on YAML Jupyter notebook opened and ready to run, as shown in Figure 2.
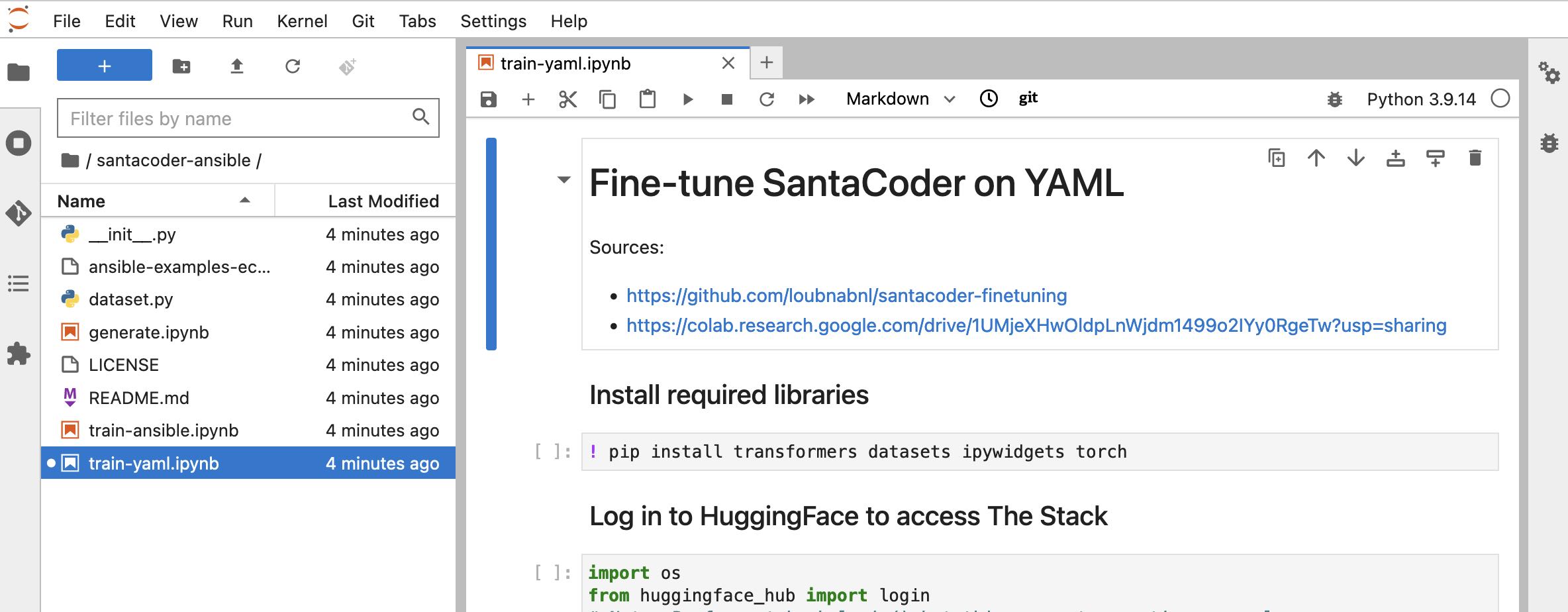
Run the file cell-by-cell, taking your time to understand each step and explore the various parameters involved. The trainer.train() step should take approximately one hour to complete. Once it's done, you'll see a new folder named santacoder-finetuned-the-stack-yaml has been created. This contains a local copy of your newly trained model, which now can generate YAML code.
To test your new model, open the generate.ipynb Jupyter notebook. Notice the first two code cells are for testing YAML or testing Ansible. You'll want to run the Test YAML cell and skip over the Test Ansible cell for now. After running this notebook, you'll see that YAML is successfully generated based on the test_input string specified in the Test YAML cell. You can switch up this variable to see different generated YAML results.
Fine-tuning on Ansible
Now that we have a model that generates YAML, our last step is to fine-tune it on Ansible content. This step is very similar to the previous one, except we will create our own dataset from scratch this time. While the models used to power Ansible Lightspeed are trained on many thousands of Ansible samples, here we are exercising a HuggingFace capability to generate a data set from the contents of a text file, in this case containing a very small number of example Ansible tasks.
Double-click and run the train-ansible.ipynb Jupyter notebook. As with the previous step, it should take about an hour to train your new model. Once complete, you'll see another folder created called santacoder-finetuned-the-stack-ansible-ec2.
Open the generate.ipynb Jupyter notebook again, this time skipping the Test YAML cell and running the Test Ansible cell. After running this notebook, you'll see that an Ansible task is successfully generated based on the test_input string specified in the Test Ansible cell (see Figure 3).
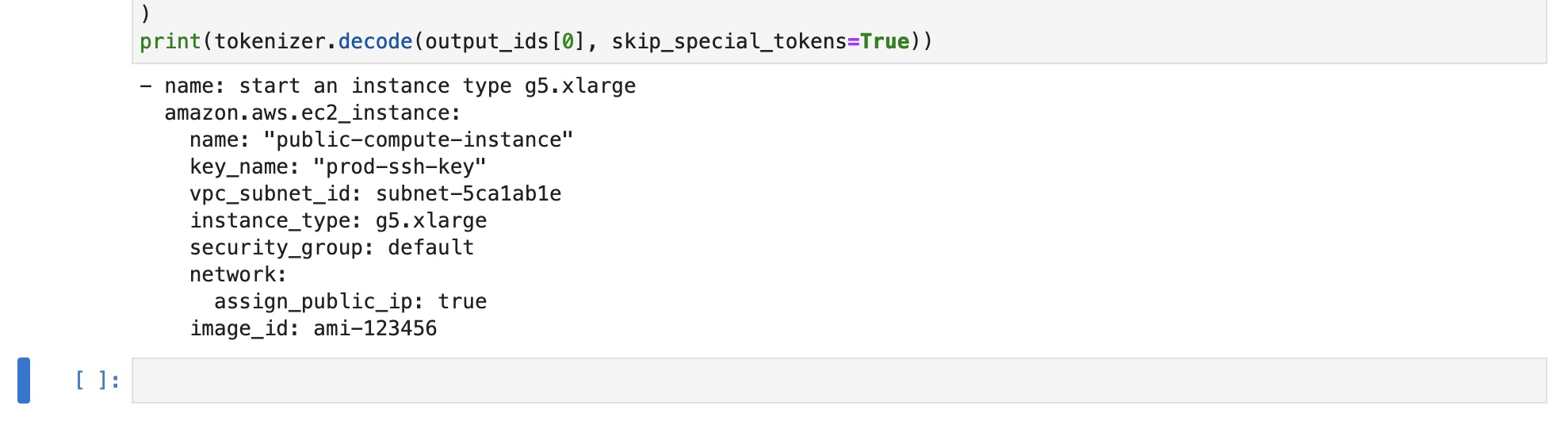
You can see in the ansible-examples-ec2.txt file that the sample tasks are all based off the amazon.aws.ec2_instance Ansible module and are nearly identical. You can try adding more interesting examples and additional modules to this file, re-training your model, and seeing what outputs you receive.
While creating a model from this extremely small set of Ansible examples is a bit contrived, I hope this article has given you an easy way to get some beginner experience with fine-tuning large language models.
OpenShift Data Science learning resources
Explore learning paths to get started with OpenShift Data Science, including:
Last updated: August 14, 2023