Overview
With OpenShift Virtualization Virtual Machines (VMs) can be run on OpenShift with bare-metal nodes - on-premises or in the cloud.
By default Kubernetes - and OpenShift - have a pretty straightforward approach for dealing with Memory: A workload is requesting memory, and then it can use it.
However, when you are running a production cluster, then the details matter. A captain needs to understand all the details - momentum, width, length, and more - of his ship in order to steer it.
In this post we are looking at how memory is provided, consumed, considered during scheduling, and the cascade of techniques in order to make efficient use of it. These details are provided in order to provide more insights and enable you to optimize it for your use-case.
The key take-aways can be found in the summary, at the very end of this post.
Memory capacity and memory requests
Node memory capacity
One primary aspect of Kubernetes - and thus OpenShift’s - scheduling concept are resources.
Every container in OpenShift is consuming some - even if very very small - amount of CPU and memory resources, because eventually, any container is mapped to a node-level process, which requires CPU and memory to run.
For this to work, Kubernetes requires two things:
- Nodes to report their (memory) resource capacity
- Containers to request a certain amount of (memory) resources
Pods can be scheduled onto a node as long as there is enough remaining capacity of a resource needed by the Pod’s containers. A node is reporting the remaining capacity as the allocatable capacity.
Node Allocatable = Node Capacity - (Sum of container memory requests on this node)
Example:
Node Capacity = 10G
Sum of container memory requests = 8 x 1G
= 8G
Node Allocatable = 10G - 8G
= 2GThese details are also shown in the Kubernetes API, on the Node objects:
kind: Node
apiVersion: v1
metadata:
name: qe-20.lab.eng.example.com
spec: {}
status:
allocatable:
memory: 584594240Ki # 558 GiB
cpu: 159500m
capacity:
memory: 1582394688Ki # 1474 GiB
cpu: '160'Important to note is, that in the case of the memory resource, only the physical amount of RAM is reported as the node's memory capacity. SWAP, compressed RAM (ZRAM), or similar are not included in this capacity.
The second important thing is to note that usually the Node object is reporting a slightly lower value than the real RAM capacity. This is, because some capacity is reserved for the operating system and hypervisor itself.
Let’s visualize this In order to give our brains and eyes something else to hold on to:

The important take aways so far are:
- Nodes are reporting their RAM capacity via the memory resource
- Workloads are requesting memory resources
- The Kubernetes scheduler is based on resource requests
- The Kubernetes scheduler is only scheduling pods once at creation time
Virtual machine memory requests
While it is generally not relevant, in this context it is relevant to note that in OpenShift, Virtual Machines are eventually run as a process inside a container, running inside a Pod. This pod is called the virt-launcher. This is because the atomic compute unit in OpenShift - and Kubernetes - is a Pod.
This Pod is created and managed - life-cycled - by KubeVirt, one component of OpenShift Virtualization. As KubeVirt is the owner of the virt-launcher pod, it is also responsible for setting its memory requests.
Let’s walk through it.
A user has created the following virtual machine using the instance type u1.2xlarge:
apiVersion: kubevirt.io/v1
kind: VirtualMachine
metadata:
name: fedora-ivory-ermine-40
spec:
instancetype:
name: u1.2xlarge
preference:
name: fedora
running: true
template:
spec:
domain:
resources: {}Upon starting this virtual machine, a VirtualMachineInstance - reflecting a running VM - is created by KubeVirt expanding the instance type into the specific resource requirements. In this case, u1.2xlarge is getting expanded into a VM with 32 GiB of (virtual) memory:
apiVersion: kubevirt.io/v1
kind: VirtualMachineInstance
metadata:
name: fedora-ivory-ermine-40
spec:
domain:
memory:
guest: 32Gi # 32 GiB
resources:
requests:
memory: 32GiThis VirtualMachineInstance is then almost immediately - also by KubeVirt - translated into a Pod:
kind: Pod
apiVersion: v1
metadata:
generateName: virt-launcher-fedora-ivory-ermine-40-
name: virt-launcher-fedora-ivory-ermine-40-h4bg5
spec:
containers:
- resources:
requests:
cpu: 800m
memory: '34739322881' # 32.35 GiB
name: computeWhen comparing the numbers between the Pod and VMI, we are seeing that the Pod hosting the virtual machine is requesting slightly more memory (32.35 GiB) than what we have defined for the guest (32GiB).
This small overhead is computed by KubeVirt in order to have sufficient space for hypervisor related overheads such as caches, and the virtual machine runtime (qemu).
A side note: Out-of-the-box two VMs with 64 GiB each do not fit onto a node with 128 GiB of ram, because a Node’s memory resource capacity is lower than its RAM capacity, and because a Pod’s memory request is higher than the virtual machine guest memory (64 GiB).
Let’s visualize this In order to give our brains and eyes something else to hold on to:

The important take aways so far are:
- Even though OpenShift can run Virtual Machines, the atomic compute unit are still Pods
- Virtual Machines are run inside Pods
- KubeVirt is building the Pods according to VM definitions
- Pods are requesting slightly more memory than what the VM needs, due to a hypervisor related reservations
Scheduler vs. Kernel
Memory requests tell the scheduler to reserve the specified amount of memory on a node for that specific workload. The scheduler is reserving memory for a workload.
However, this reservation is only a logical reservation on the scheduler level. There is no enforcement of this reservation on the node level.
Given a workload requesting 4 GiB of memory, the scheduler will reserve 4 GiB of memory on a node by reducing the allocatable capacity by 4 GiB.
Once the workload is running on that node, then the node is not enforcing this 4GiB reservation and the workload can use more or less than these 4 GiB.
Limits
If you have read about Kubernetes and OpenShift, then you will also have come across the term limits in the context of memory, resources, and alike. Limits are Kubernetes' tool to constrain resource consumption on the node level. Memory limits in particular can put virtual machines at risk of being killed.
The good news is that OpenShift Virtualization can set appropriate limits automatically for you on selected namespaces.
The important take aways so far are:
- OpenShift Virtualization can set memory (and CPU) limits automatically if needed
- Do not explicitly set memory limits on a virtual machine unless you really, really, know what you are doing
- Set memory on VirtualMachine objects only via the memory.guest field
Reservation and utilization
We have seen that Kubernetes requires workloads to express upfront how many memory resources they are expected to be using at runtime. Thus it’s only an estimate, and not the real usage of resources at runtime.
If requests are the memory reservation of a workload, then utilization is the actual usage of memory at runtime.
In the real world it is actually pretty difficult to estimate how much memory a workload really needs at any given point in time. The world is diverse - thus there are for sure workloads where we know pretty well how much memory is consumed, but on the other side of the spectrum we will find workloads where we have no idea - or - where the requirements are vividly changing.
Important to note here is that the utilization can be quite different to the reservation of a workload. And this is adding up if we zoom out and look at the node level.
One workload consuming only 50% of their reservation might not be an issue. But having all workloads on a node using only 50% of their reservation is an issue, because this in turn means that 50% of the node are not utilized.
A side note: Vividly changing demands - spikes - actually influenced the core principles of Kubernetes and stateless (12 factor) applications: Meet spikes by scaling out. In some way scaling out is simple, because it’s not changing any existing workload, but only adding (or later removing) reservations. But let me get back on track.
Let’s visualize this In order to give our brains and eyes something else to hold on to:
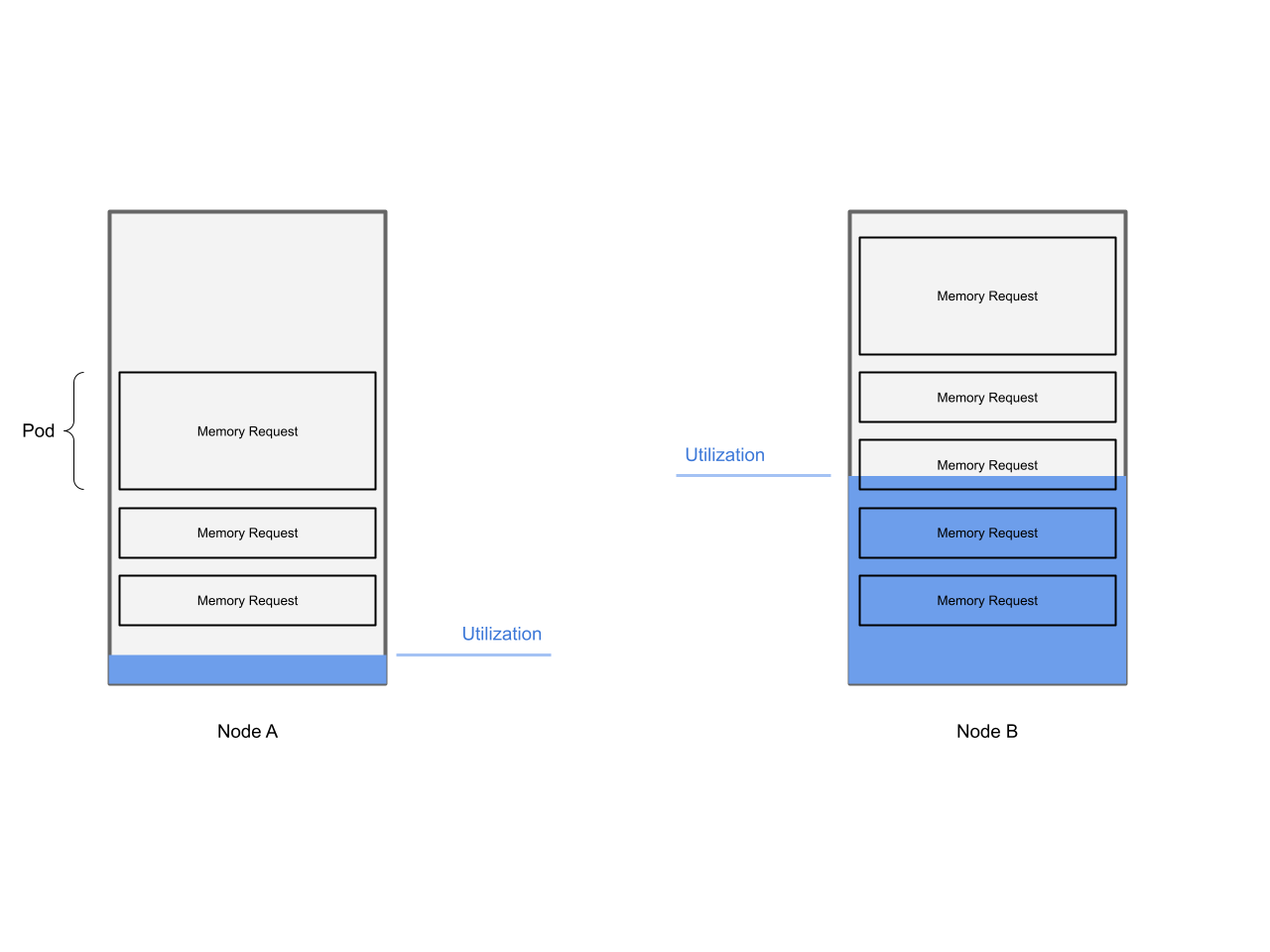
The important take aways so far are:
- A workloads utilization can be quite different from its reservation
- At scale a low utilization is leading to inefficient use of resources
- A low memory utilization does not allow more workloads to be scheduled on a node
Higher workload density
Given this system, what can we do in order to increase the resource utilization (of a single node, or of the cluster)?
Let me pull up the two most important essentials from this post so far in order to get to an answer:
- Nodes report their available RAM (only) as memory
- Pods request memory to run virtual machines
And we really have just two options:
a. Extend a node’s RAM in order to report more memory resource
b. Reduce a workload’s memory request
Kubernetes is pretty strict about what it is reporting as memory. Today it is limited to reporting the physical RAM of a node. Nothing else. And because we can not really change the reported memory capacity, option (a) is not a tool to achieve a higher density.
While option (b) is phrased in a quite Kubernetes specific way (“reducing workload memory requests”), the overall concept "reserves less memory for a given workload” is a virtualization industry standard for decades and well known as “memory over commitment."
OpenShift Virtualization is following the same pattern and is achieving memory overcommitment by requesting less memory for a virtual machine.
Let’s visualize this In order to give our brains and eyes something else to hold on to:
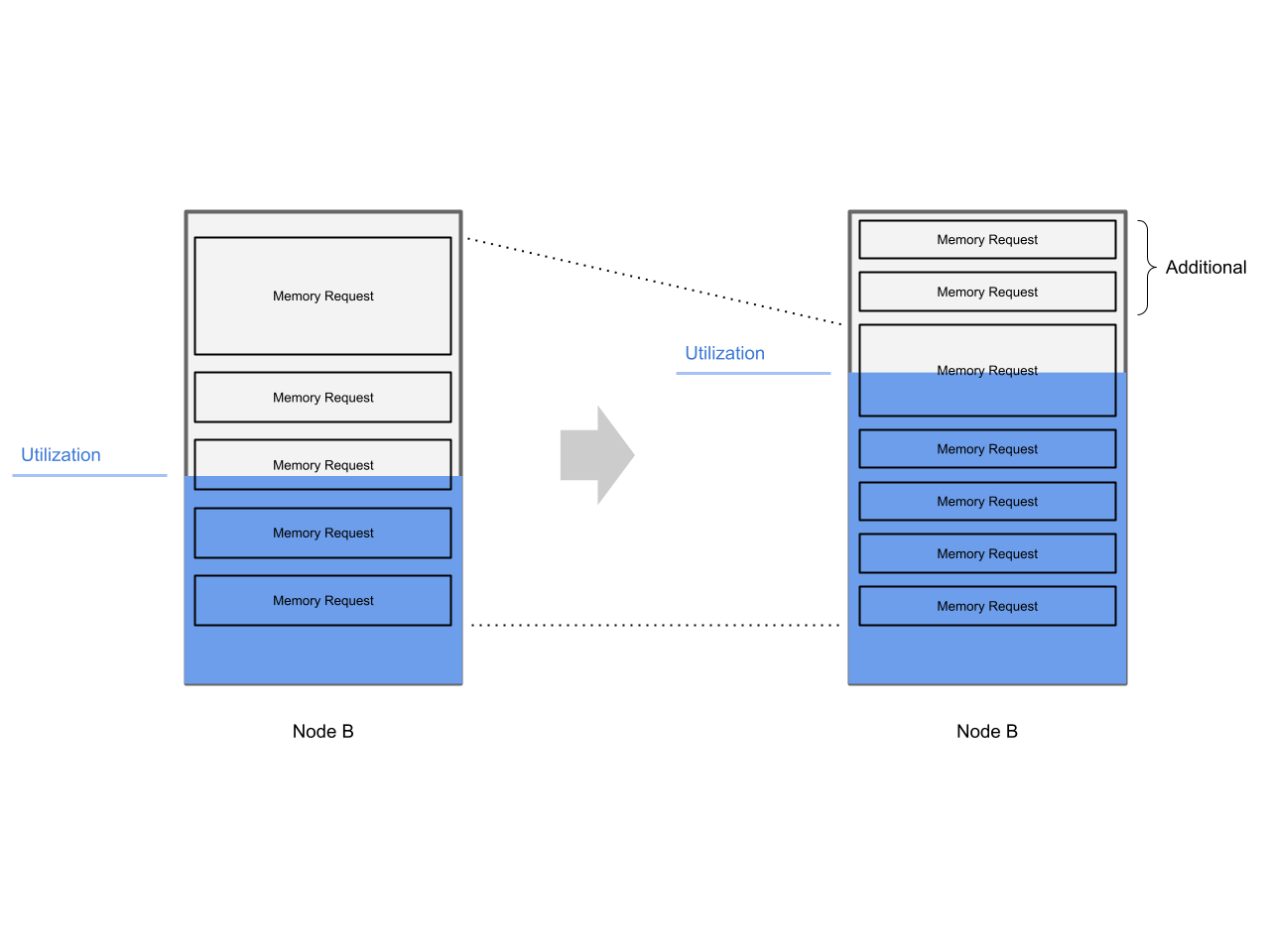
Reducing the memory requests for a workload seems to be pretty easy: Just reduce the requests. True, that it is easy to achieve. But what is the effect of this configuration change?
If your virtual machine has 9 GiB of (virtual) memory, and you are reducing the memory requests (the reservation) to 6 GiB, then no memory reservations exist for the delta of 3 GiB of the virtual memory.
This means that 6 GiB of memory are reserved by Kubernetes for this workload, the remaining 3 GiB are not reserved - this is the over committed memory - and needs to be taken from somewhere.
We’ll pick this up in a minute again.
Configuring a higher workload density in OpenShift Virtualization
OpenShift Virtualization provides memory overcommitment, but it is disabled by default.
A cluster administrator can run the following command in order to make memory overcommit the default for every workload in OpenShift:
$ oc -n openshift-cnv patch HyperConverged/kubevirt-hyperconverged --type='json' -p='[ \
{ \
"op": "replace", \
"path": "/spec/higherWorkloadDensity/memoryOvercommitPercentage", \
"value": 150 \
} \
]'
hyperconverged.hco.kubevirt.io/kubevirt-hyperconverged patched
$Internally this is working quite simple: The memory assigned to the guest (memory.guest) is getting proportionally adjusted according to the memoryOvercommitPercentage value:
memory.guest = 12 GiB
memoryOvercommitPercentage = 150
requests.memory = memory.guest * 100 / memoryOvercommitPercentage
= 12 GiB * 100 / 150
= 8 GiBAdjusting requests.memory and memory.guest manually on a VM object - is not recommended, but - will lead to the same results. Furthermore this workload level manual approach allows to override the cluster default and achieve a higher or lower over commitment.
At the same time this shows that it is mandatory that a workload is defining memory.guest only in order to receive the cluster default memory over commitment configuration.
The important take aways so far are:
- Lowering memory requests of workloads is they key for a higher workload density on OpenShift
- Setting the cluster level memoryOvercommitPercentage value will lead workloads to use memory overcommitment
- The cluster default memory over commitment can be overridden by setting memory.guest and requests.memory manually on the VM level. This is not recommended.
Reducing memory utilization
We said the over committed memory needs to be taken from somewhere.
And the idea is to take this memory from other workloads. To use the capacity that other workloads are currently not using.
We have a VM with 9 GiB of memory, this is backed by 6 GiB of memory requests.
At some point this VM really needs 9 GiB of memory. Thus an additional 3 GiB of memory needs to be taken from somewhere in order to provide it to the 9 GiB VM.
Luckily on the same node there is a 12 GiB VM (with 8 GiB memory requests), and it’s actually idling at a memory utilization of 4 GiB. Thus the VM is using 4 GiB less than it has reserved.
The 9 GiB VM can not easily use this memory, which is unused by the 12 GiB VM.
Let’s visualize this In order to give our brains and eyes something else to hold on to:
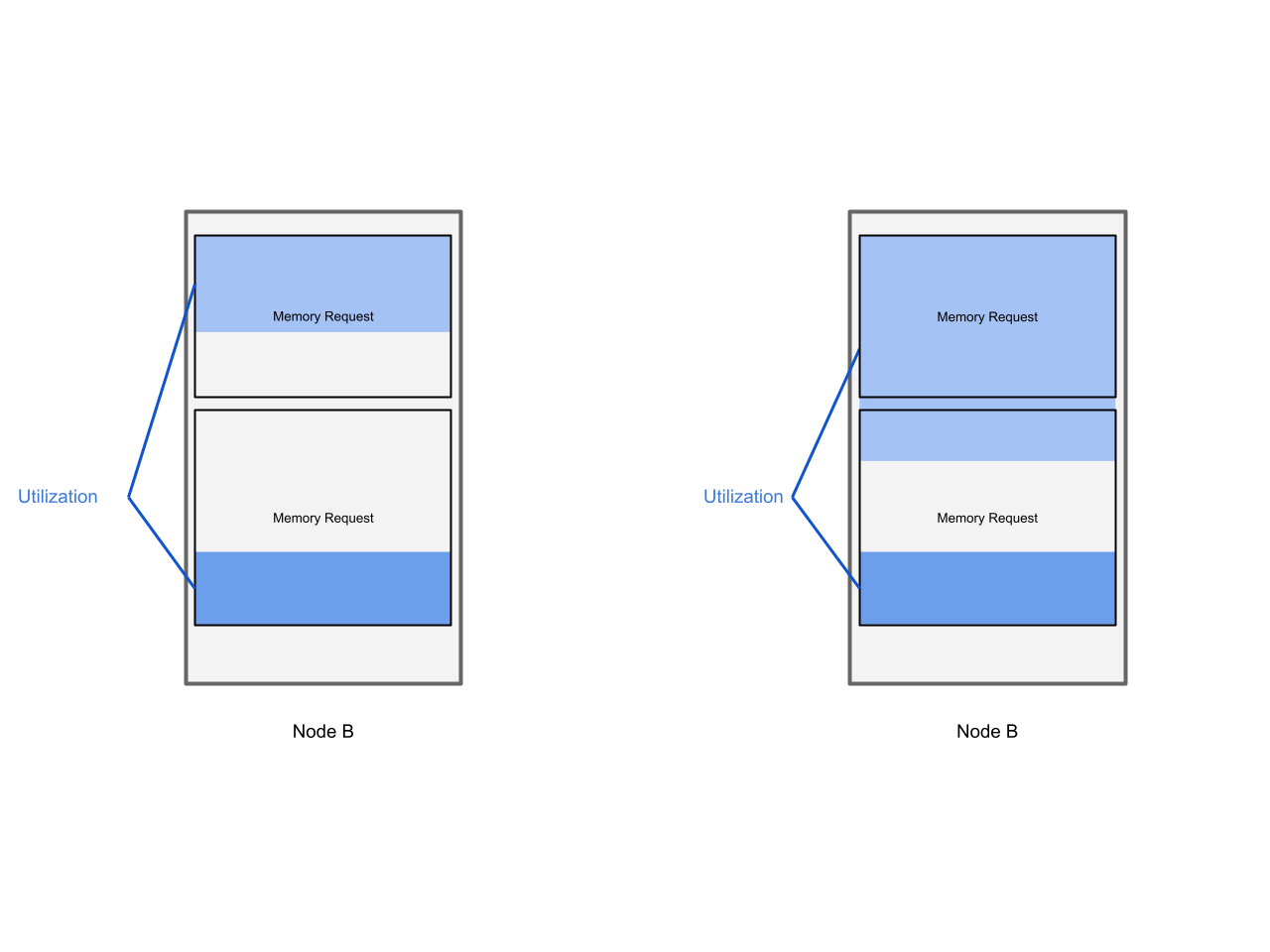
Important things to note:
- Allocation of memory is happening dynamically and transparent to the VM
- Allocation of memory is also transparent to Kubernetes and OpenShift
- Allocation, freeing, and reallocation of memory is nothing special and is a normal operating system task.
In addition to the dynamic allocation of memory to workloads, OpenShift Virtualization is employing two techniques in order to actively reduce the memory footprint of a VM and with that further avoiding memory pressure:
- Free Page Reporting, also known as FPR
- Kernel Same Page Merging, also known as KSM
Let’s look at each of them.
Free Page Reporting (FPR)
Free Page Reporting allows the hypervisor to see when a guest is not using its memory. The hypervisor can then use this memory and provide it to other VMs (and processes on that node) as needed.
Inside the guest the ballooning driver - part of the virtio driver family - is responsible for reporting free pages via the qemu guest-agent to the hypervisor.
FPR depends on the guest to report the memory pages that it is not using.
FPR is enabled by default, but requires the ballooning driver to be present inside the guest OS.
Kernel Same Page Merging (KSM)
Kernel Same Page merging is a host only technique. If KSM is activated, the Kernel will periodically look for identical VM related memory pages. If it does find a duplicate memory page, then these pages are merged into a single page thus freeing memory of every duplicate that is found.
If a process changes this page, the kernel is duplicating that page with the change again in order to reflect that change.
KSM is specifically helpful in scenarios where many similar VMs (e.g. Windows Workstations) are running on the same node.
However, the memory deduplication, and replication (if a write is taking place) is slowing down memory operations in general (due to the scans, de-duplication and copies happening).
In theory this could also help timing attacks to succeed and with that could be a security consideration as well..
Due to this, KSM is disabled by default, it can be enabled if needed, and the environment permits it.
Incorrect reservations
There is actually a third reason why there is often enough memory available on a node: Incorrect memory reservations.
It turns out that memory reservations are quite conservative. Thus if in question, then VM owners tend to assign more memory to a VM then it might need.
This oversizing of memory requests is therefore providing “unused” memory reservations to nodes.
The important take aways so far are:
- FPR and KSM are techniques to reduce the memory utilization of VMs in order to keep more free memory around
- Oversized memory requests contribute unused memory to nodes.
Diffusing memory utilization
In order to speak about avoiding the worst case, we should first speak about what the worst case is.
The worst case is if workloads are becoming unavailable.
This can be caused by 2 things: The workload itself is becoming unavailable, or the hypervisor becoming unavailable making any otherwise healthy workloads unavailable.
One cause of this is running out memory, either a specific workload, or system critical daemons.
We now have nodes with over committed memory, however due to the techniques to lower VM memory utilization, and because of incorrect memory request sizing, those workloads usually still have sufficient memory to operate normally.
But “usually” is usually not a good way to provide guarantees in enterprise environments.
In this section we look at preparing for the worst case: All VMs need all the memory that we granted to them - thus all VMs will be exceeding their reserved memory at the same time.
Without extra measures a node will be running out of RAM, leading to Out-Of-Memory errors and killing of workload. This is not acceptable and the administrator wants to have some time to react before that happens.
SWAP
Thus, because we can not extend the physical RAM, we can look at extending the virtual memory.
The virtual memory - or address space - is the memory that the Linux kernel has available to manage processes’ memory.
By default the virtual memory is equal to the physical RAM. The virtual memory can be extended by providing swap.
Thus swap is used in order to provide enough virtual memory in order to provide enough virtual memory to all VMs that are currently running on a node.
Swap and RAM and not treated equally by the Kernel, the Kernel has heuristics in order to keep “hot” (often used) memory in RAM, and “cold” (less often used) memory on swap, because swap is showing a significantly slower performance compared to RAM.
A workload user is usually observing a degradation in performance once a workload is starting to be swapped out to swap.
Due to the performance impact it’s usually in the interest of an administrator to prevent swapping to occur at all, yet it is kept around for the worst case.
SWAP In OpenShift
Because SWAP is not yet generally available in Kubernetes, OpenShift Virtualization is providing a small component - WASP - in order to provide swap to virtual machines.
Technically, swap is configured independently of memory overcommit, however, it is recommended to always enable swap in the case of memory over commit in order to ensure that there is some time to react to a memory pressure situation.
In other words: SWAP is used in order to complement the physical memory and jointly form a larger virtual memory. The virtual memory is recommended to be large enough to back all the virtual memory provided to virtual machines.
It’s been a while, thus: Let’s visualize this In order to give our brains and eyes something else to hold on to:
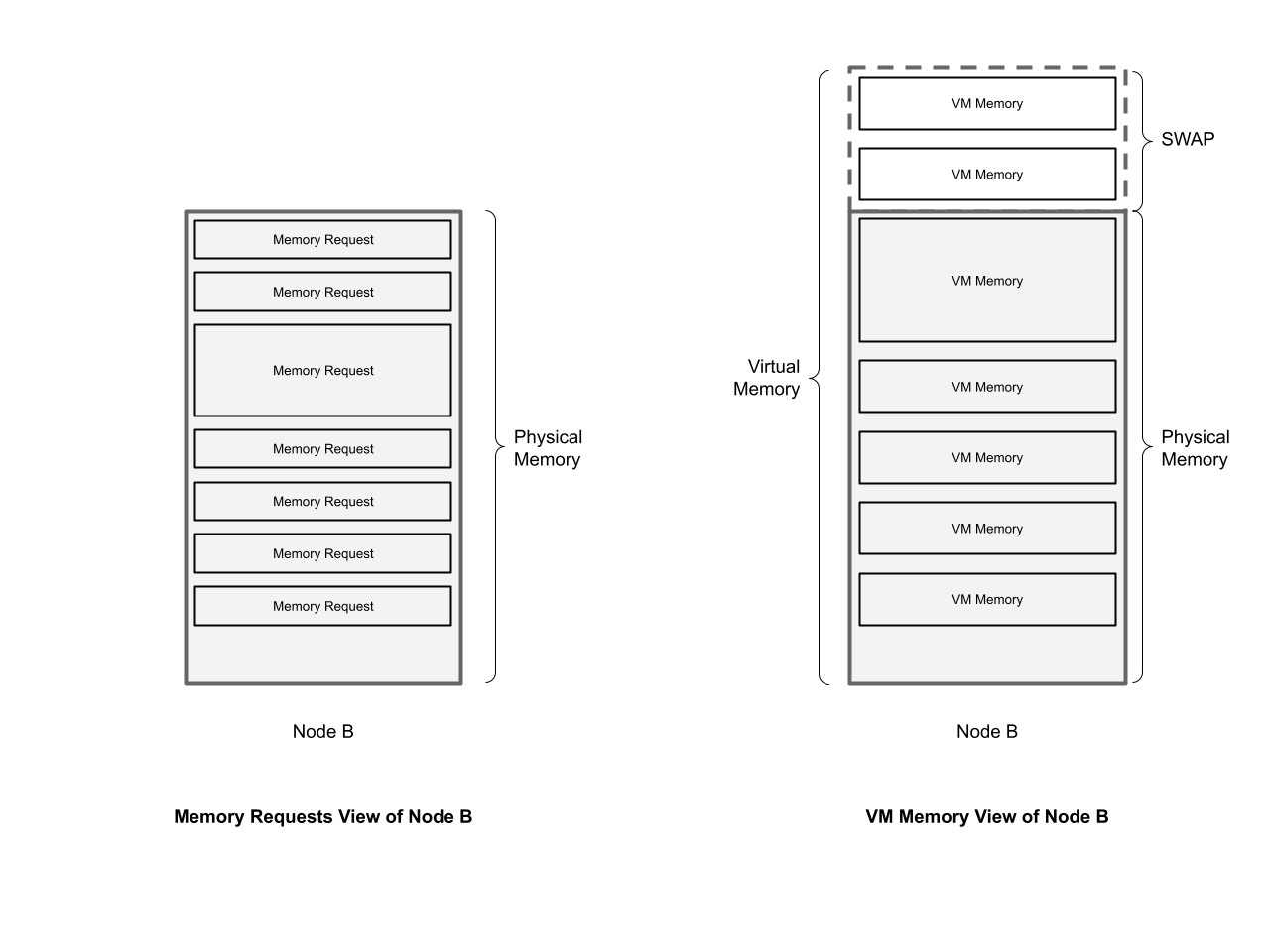
The important take aways so far are:
- SWAP is complementing physical memory, together they form the virtual memory
- SWAP should be used when memory over commitment is enabled
Kubernetes descheduler
Even if SWAP ensures that there is enough virtual memory available in order to meet requests exceeding physical memory, it is generally also a goal to avoid using swap.
The reason for this is that swap usually resides on disks, which are magnitudes slower than physical RAM. Thus whenever swap is used, memory operations relating to swap will have a significantly increased memory latency, leading to a sluggish (at best) or frozen (at worst) system. You might know this feeling.
FPR and KSM are two mechanisms to reduce the node local memory consumption.
The descheduler is provided in order to use a different strategy: Even if the memory is already used efficiently on the local node, then there might be a node in the cluster which still has some free capacity, thus let’s move the VM away from the node where we have some memory pressure.
The descheduler only gained this feature - node load awareness - just recently.
The essence of this new feature is to monitor the pressure that workloads are experiencing on a node. If the pressure is too high, the node is taken out of scheduling (by using Kubernetes taints), and workloads are evicted from the affected node in order to reduce the pressure on that overloaded node.
The descheduler is responsible for identifying overutilized nodes, taint them, and evict workloads in order to reduce the pressure on the node thus automating the tasks an admin would do once they realize memory pressure on their nodes.
Let’s visualize this In order to give our brains and eyes something else to hold on to:
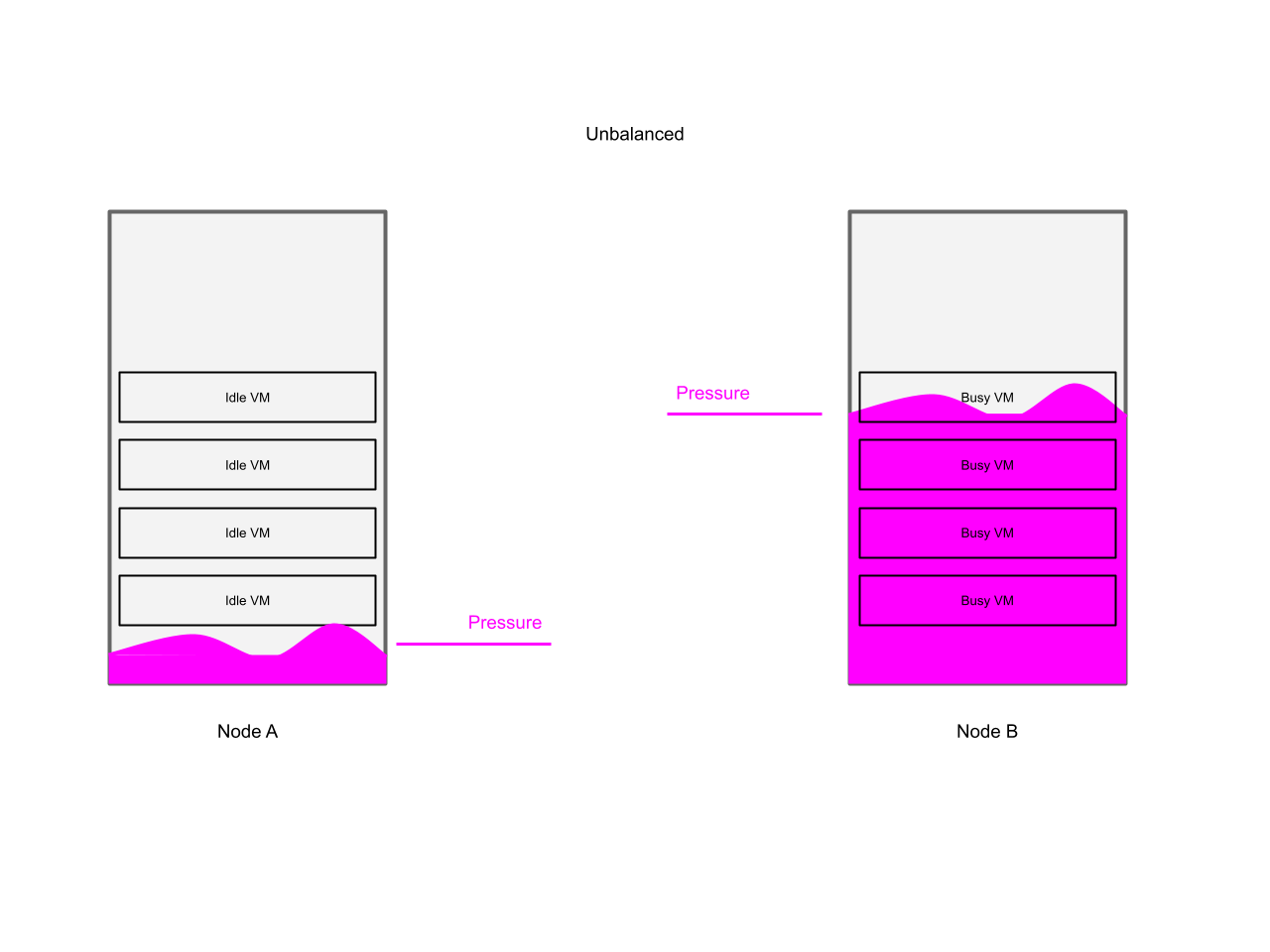
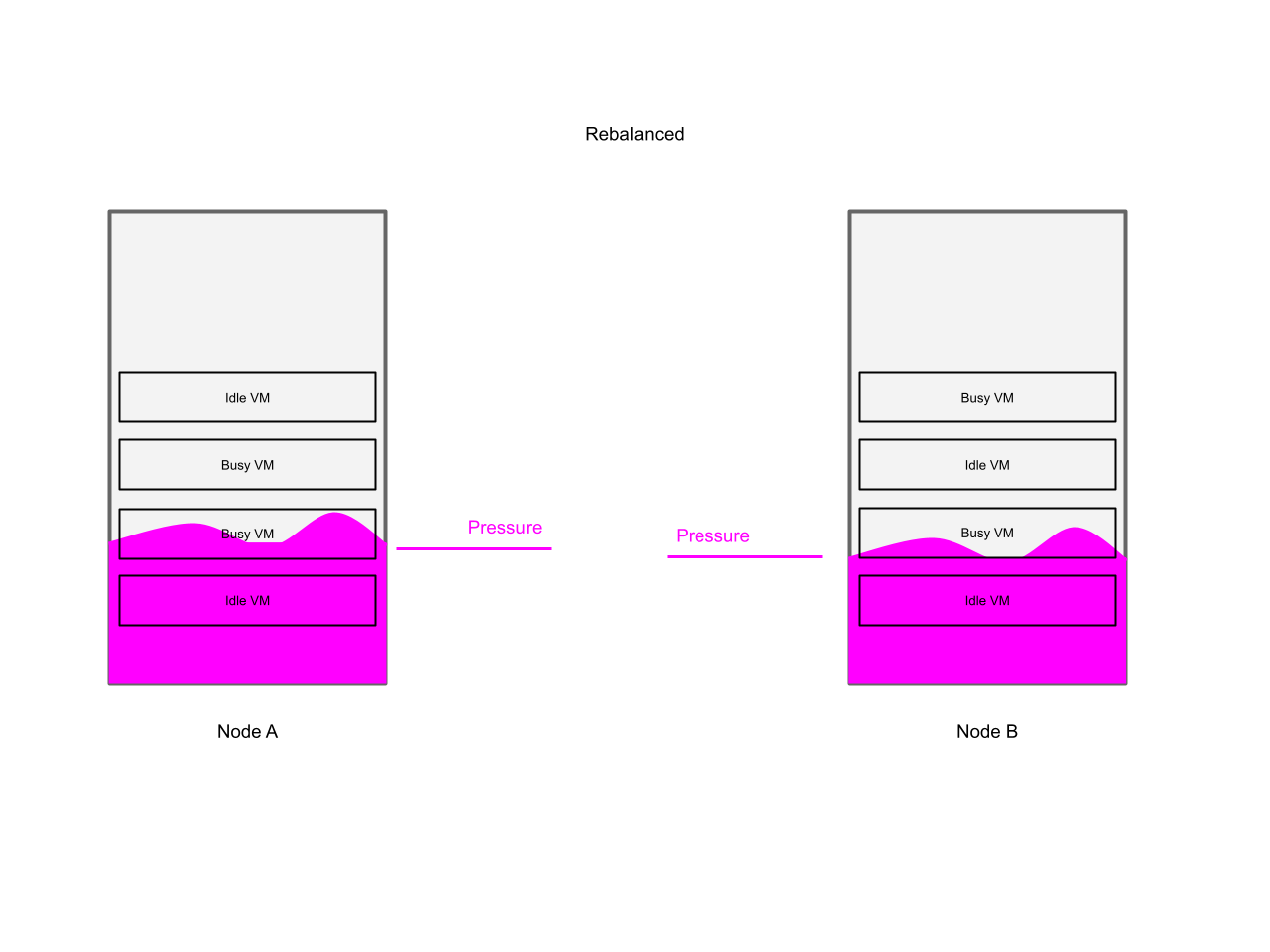
The important take aways so far are:
- The descheduler is monitoring workload pressure on nodes, and evicting workloads if necessary to reduce node level pressure
- At scale this leads to leveling out pressure across all workers of a cluster
Memory pressure reduction
Node-pressure eviction
Node-pressure eviction is a node-local eviction mechanism (commonly confused with cluster level eviction) in order to evict pods once the node is getting under pressure. Node-pressure can occur for non-compressible resources, such as memory, storage, and the number of PIDs (because there is a limit to how many processes can be run simultaneously).
Thus if any of these resources is getting under pressure, Kubernetes (the kubelet) will take a pod and evict it. Eviction in this case is the request to shutdown workload in an admin defined grace period.
There are two variants of node-pressure eviction:
- soft eviction - terminating workloads after a grace period
- hard eviction - terminating workloads without a grace period
While soft eviction is currently not used by default, hard eviction is configured by default.
Out-Of-Memory
You are still with us? Congratulations. You are now rewarded with a rather short section.
If you are really running out of memory, which is really really rare, then the virtual machine will be terminated. This is, in order to protect the whole node from becoming unavailable - which would mean that all virtual machines on that node become unavailable.
Summary
In this post we looked at how memory management of Virtual Machines in OpenShift Virtualization is working, and what mechanisms exist in order to prevent and deal with memory pressure.
From a high level there are two things to note:
- Cluster administrators and workload owners have tight control over the cluster and workload memory configuration if needed
- By default, OpenShift Virtualization is not performing memory over commitment, but using FPR to use memory efficiently. Optionally KSM, SWAP, and the descheduler are available in order to reduce or distribute memory utilization even more.
- Memory over commitment requires swap and can be enabled optionally.
The important take aways so far are:
- The Memory of Virtual Machines should only be configured using the memory.guest field.
- Kubernetes and OpenShift are exposing the physical memory (RAM) as the memory resource.
- Scheduling of pods is based on memory requests (resources.requests.memory).
- Today the only way to achieve a higher workload density is to reduce the memory requests of a workload. On a workload or cluster level.
- FPR and KSM are mechanisms to reduce memory utilization on nodes in order to prevent memory pressure.
- SWAP is a mechanism to extend the virtual memory in order to have sufficient space for all workloads.
- descheduler is distributing workloads across cluster nodes according to node pressure.
- Node-pressure eviction is a node level protection mechanism kicking in once nodes get under resource pressure.
