The latest release of Apache Kafka, 3.6.0, introduced a major new feature: tiered storage.
This long-awaited feature, first proposed in 2019 via KIP-405, is finally available in early access. It has been a tremendous effort by the Kafka community to reach this milestone, with dozens of contributors from various companies, including Red Hat, collaborating to design, implement, and test this feature.
As mentioned, tiered storage is currently available in early access, so it should not be used for production use cases. This first version has a number of limitations, including no support for brokers with multiple logs directories (JBOD), no support for compacted topics and there is no way to disable it once it's enabled on a topic. There is still a lot of ongoing work in Apache Kafka to improve this feature, including several Kafka Improvement Proposals (KIP-950, KIP-958, KIP-963).
In this article I'll explain what tiered storage is, the benefits it brings, and demonstrate how to use this feature.
What is tiered storage?
Tiered storage is an interesting feature as it brings several significant improvements to Kafka and enables novel use cases. In a nutshell, tiered storage means that older data gets migrated to cheaper off-broker storage.
When producers send records to Kafka, brokers store them in append-only files, called log segments, on disks. The size of the disks attached to brokers limits how much data a cluster can store. For this reason, administrators use size and time retention policies (via log.retention.bytes and log.retention.ms) to regularly delete records and control how much data is stored.
Until now, administrators had two options if they wanted to store more records:
- Add more disks or larger disks to brokers. Kafka supports using multiple log directories (JBOD). Adding large disks can be expensive, and when using multiple log directories, you might need to regularly move partitions between the disks to balance usage across them. Another thing to consider is the operational cost of having very large disks. When a broker shuts down unexpectedly, it checks its log directories upon restarting, and this can take minutes to complete for a very large disk containing many partitions. Similarly, replacing a multi-terabytes failed disk can cause a lot of overhead on a cluster as all the log segments from all the partitions it hosted have to be copied back onto the new disk from other brokers.
- Use an integration tool like Kafka Connect to copy records into a separate system before deleting them from Kafka. Obviously this comes at the cost of maintaining an extra tool, and you also need a process to reingest the data in case you need it later in Kafka.
Tiered storage solves these issues by offering a built-in mechanism in the brokers to move log segments to a separate storage system. This is completely invisible to Kafka clients as log segments on the remote storage system can still be accessed by Kafka consumers as if they were on local disks.
Cloud object storage systems such as Amazon S3 are a great match for this feature, as they offer cheap and almost unlimited storage. For example, if your consumer applications are typically near the end of partitions, you can have small and fast disks on your brokers to quickly serve the latest records and have older data stored in S3, which offers a much cheaper cost per GB of data than solid state disks. Note that consuming records that are stored on the storage system will often come with a small increased latency as brokers first have to retrieve them.
Due to the number of existing storage systems, Apache Kafka provides a pluggable interface for tiered storage. Kafka only comes with two example implementations (one storing records in memory and one storing records on the local filesystem) that demonstrate how to use the API. It's up to the community and vendors to build plug-ins for their preferred storage systems.
Now, let's set up a Kafka cluster using Amazon S3 for its tiered storage.
Build the Aiven tiered storage plug-in
One of the most promising plug-ins available today is tiered-storage-for-apache-kafka by Aiven. This plug-in supports Amazon S3, Azure Blob Storage, and Google Cloud Storage as storage system back ends. No releases are available yet, so we need to build it ourselves. In order to do so, you need the following tools:
- Git
- make
- Java >= 11
Follow these steps:
- First, clone the repository:
$ git clone https://github.com/Aiven-Open/tiered-storage-for-apache-kafka.gitThe plug-in is still under development. All the commands below have been tested at this commit: 3b44bd9.
- Build the plug-in:
$ cd tiered-storage-for-apache-kafka $ make build - Extract the distribution archives to the desired directory, for example,
/opt/tiered-storage/*. The common JARs are in the archive underbuild/distributions, and the JARs specific to each back end are in their respective directory understorage(s3,azureandgcs). Here we will copy the S3 distribution, as it's the back end we are using.
$ cp build/distributions/tiered-storage-for-apache-kafka-*.tgz /opt/tiered-storage && tar xf tiered-storage-for-apache-kafka-*.tgz --strip-components=1 && rm tiered-storage-for-apache-kafka-*.tgz $ cp storage/s3/build/distributions/s3-*.tgz /opt/tiered-storage && tar xf s3-*.tgz --strip-components=1 && rm s3-*.tgz
Set up an S3 Bucket and IAM credentials in AWS
The next step is to get a bucket in Amazon S3 and create a user in IAM:
- Open the S3 console: https://s3.console.aws.amazon.com/s3/home
- Click the Create Bucket button and fill in details. Take note of the bucket name and the region you select.
- Next, navigate to the IAM console: https://console.aws.amazon.com/iamv2/home
- Click Users on the menu on the left, then click the Create user button and fill in details. Be sure to grant enough permissions to use S3.
- Select the user you created and under the Security credentials tab, click Create access key and fill in details. Take note of the access key ID and secret access key.
Set up a Kafka cluster
We now need to configure a Kafka cluster to use the plug-in. In this example, we use a single broker running in KRaft mode.
Download and extract Kafka 3.6.0:
$ wget https://downloads.apache.org/kafka/3.6.0/kafka_2.13-3.6.0.tgz
$ tar xf kafka_2.13-3.6.0.tgz
$ cd kafka_2.13-3.6.0Let's start by enabling tiered storage and adding the common configurations to config/kraft/server.properties:
remote.log.storage.system.enable=true
remote.log.storage.manager.class.path=/opt/tiered-storage/*
remote.log.storage.manager.impl.prefix=rsm.config.
remote.log.storage.manager.class.name=io.aiven.kafka.tieredstorage.RemoteStorageManager
remote.log.metadata.manager.impl.prefix=rlmm.config.
remote.log.metadata.manager.listener.name=PLAINTEXT
rlmm.config.remote.log.metadata.topic.replication.factor=1See the Kafka documentation for the full list of configurations related to tiered storage.
Then, in the same file, we also need to add the configurations specific to the Aiven plug-in and the S3 backend:
rsm.config.storage.backend.class=io.aiven.kafka.tieredstorage.storage.s3.S3Storage
rsm.config.chunk.size=5242880
rsm.config.storage.s3.bucket.name=<BUCKET_NAME>
rsm.config.storage.s3.region=<REGION>
aws.access.key.id=<ACCESS_KEY_ID>
aws.secret.access.key=<SECRET_ACCESS_KEY>Be sure to replace <BUCKET_NAME>, <BUCKET_REGION>, <ACCESS_KEY_ID>, and <SECRET_ACCESS_KEY> with the values you obtained from S3 and IAM.
You can now start the Kafka cluster:
$ KAFKA_CLUSTER_ID="$(bin/kafka-storage.sh random-uuid)"
$ bin/kafka-storage.sh format -t $KAFKA_CLUSTER_ID -c config/kraft/server.properties
Formatting /tmp/kraft-combined-logs with metadata.version 3.6-IV2.
$ bin/kafka-server-start.sh config/kraft/server.propertiesTesting tiered storage
We start by creating a topic with tiered storage enabled. We also specify:
local.retention.ms: This is the duration in milliseconds to keep a log segment on disk once it has been copied to the remote storage. It defaults to-2which means using the value oflog.retention.ms. We set it to 1000 to quickly delete log segments from the broker's disk and validate our consumer can read records moved to remote storage.segment.bytes: This is the size of log segments. We set it to a small value so it's quick to fill segments.
$ bin/kafka-topics.sh --bootstrap-server localhost:9092 \
--create --topic test \
--partitions 1 --replication-factor 1 \
--config remote.storage.enable=true \
--config local.retention.ms=1000 \
--config segment.bytes=1000000
Created topic test.Let's produce a few records to the topic:
$ bin/kafka-console-producer.sh --bootstrap-server localhost:9092 \
--topic test
>helloThen press Ctrl+C to stop the console producer.
In order to trigger some data to be copied to the S3 bucket, we at least need to fill a segment. To do so, we can use the kafka-producer-perf-test tool. For example:
$ bin/kafka-producer-perf-test.sh --topic test \
--producer-props bootstrap.servers=localhost:9092 \
--num-records 1000 \
--throughput -1 \
--record-size 1024
1000 records sent, 2150.537634 records/sec (2.10 MB/sec), 31.22 ms avg latency, 332.00 ms max latency, 29 ms 50th, 43 ms 95th, 96 ms 99th, 332 ms 99.9th.Now that a log segment is full, the broker will start uploading it to S3 in the background. Once it's complete, you should see a message in the broker logs:
INFO [RemoteLogManager=1 partition=OVYZyPB-TWOEvoH7r8E2dg:test-0] Copied 00000000000000000000.log to remote storage with segment-id: RemoteLogSegmentId{topicIdPartition=OVYZyPB-TWOEvoH7r8E2dg:test-0, id=tp70QcLQSeed9tvj5KR0Pg} (kafka.log.remote.RemoteLogManager$RLMTask)In the S3 console, you should see some folders and files, as shown in Figure 1.
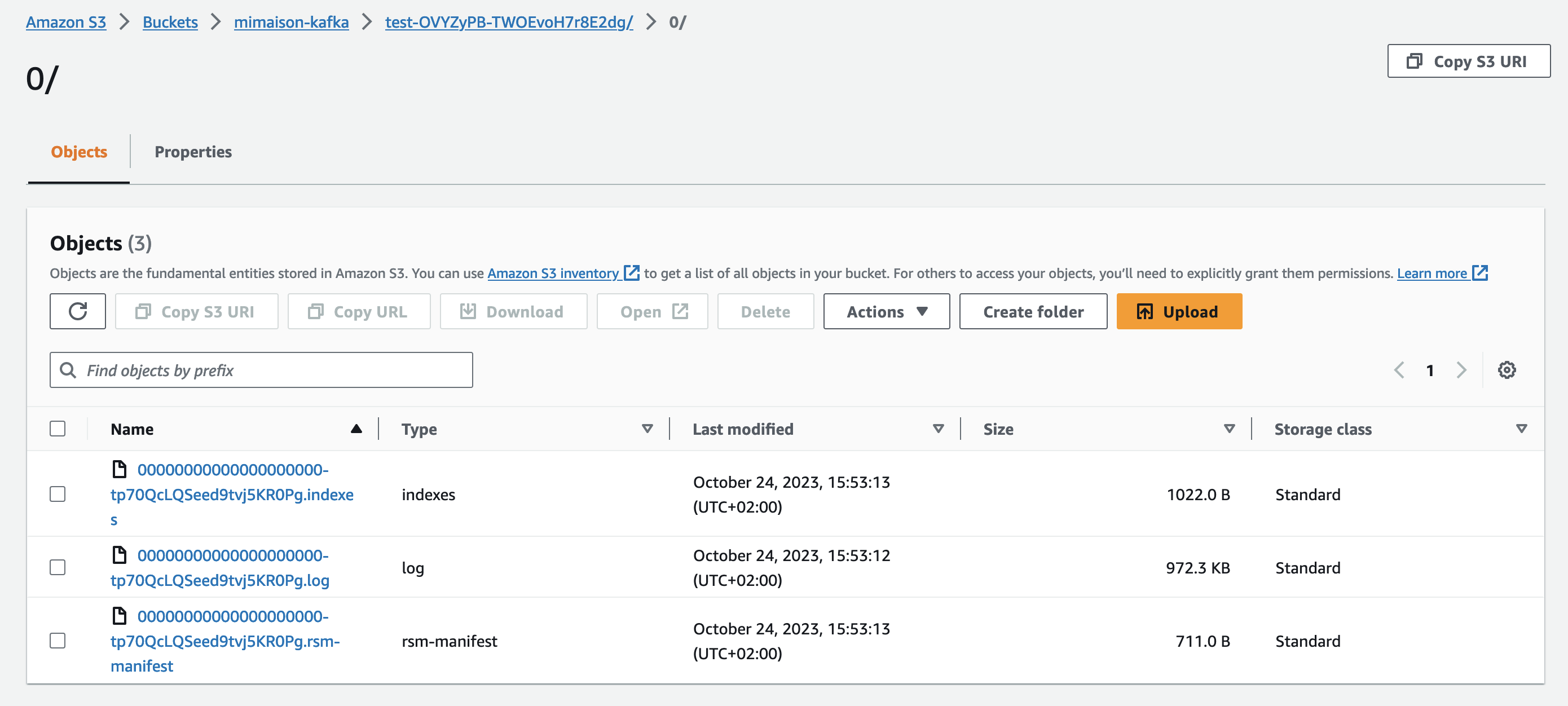
The first folder, test-OVYZyPB-TWOEvoH7r8E2dg, is named from the topic name, test, followed by a dash and the topicId, OVYZyPB-TWOEvoH7r8E2dg. You can see the topicId for a topic by using the kafka-topics tools:
$ bin/kafka-topics.sh --bootstrap-server localhost:9092 \
--describe \ --topic test
Topic: test TopicId: OVYZyPB-TWOEvoH7r8E2dg PartitionCount: 1 ReplicationFactor: 1 Configs: remote.storage.enable=true,local.retention.ms=10000,segment.bytes=1000000
Topic: test Partition: 0 Leader: 1 Replicas: 1 Isr: 1The second folder is the partition number, in this case 0 as our topic has a single partition. The files within this folder are named from the log segment. The first 20 digits indicate the starting offset, in this case 0 as it's a new topic, for this segment.
In this example, the files are:
00000000000000000000-tp70QcLQSeed9tvj5KR0Pg.indexes: This file maps to the Kafka indexes files that are associated with each log segment in Kafka.00000000000000000000-tp70QcLQSeed9tvj5KR0Pg.log: This is the log segment that contains the Kafka records.00000000000000000000-tp70QcLQSeed9tvj5KR0Pg.rsm-manifest: This file contains metadata about the log segment and indexes.
If we download the log file, in this case 00000000000000000000-tp70QcLQSeed9tvj5KR0Pg.log, we can confirm it contains the data from our topic:
$ head -c 100 00000000000000000000-tp70QcLQSeed9tvj5KR0Pg.log
=T8rT�a�)�a�)
hello<�[�%We can also run a consumer configured to read from the start of the topic and retrieve our first record:
$ bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 \
--topic test \
--from-beginning \
--max-messages 1
hello
Processed a total of 1 messagesConclusion
This article demonstrated how to use tiered storage with Kafka. While this feature is not yet ready for production use cases, you can start experimenting with it and gauge if this is a feature you want to adopt once it's production ready. You can find more details in the early access release notes or follow progress on the Jira ticket in the Kafka bug tracker.
